
seq2seq Model
The Sequence-to-Sequence (Seq2Seq) model is a type of neural network architecture widely used in machine learning particularly in tasks that involve translating one sequence of data into another. It takes an input sequence, processes it and generates an output sequence. The Seq2Seq model has made significant contributions to areas such as natural language processing (NLP), machine translation and speech recognition.
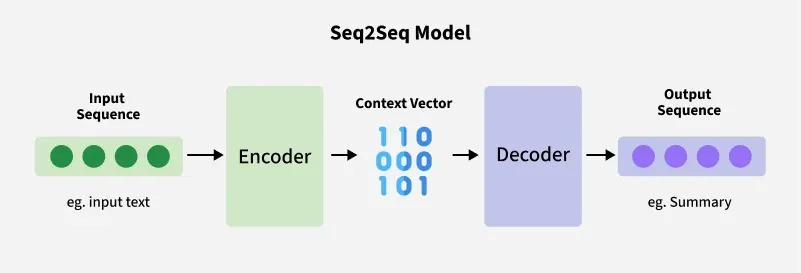
Both the input and the output are treated as sequences of varying lengths and the model is composed of two parts:
- Encoder: It processes the input sequence and encodes it into a fixed-length context vector or series of hidden states.
- Decoder: It uses this encoded information (context vector) to generate the output sequence.
Note: To learn more on this topics refer this article : Encoder Decoder
The model is commonly used in tasks where there is a need to map sequences of varying lengths such as converting a sentence in one language to another or predicting a sequence of future events based on past data i.e time-series forecasting.
Seq2Seq with RNNs
Here
[Tex]h_t [/Tex] represents hidden state at time step t[Tex]x_t [/Tex] represents input at time step t[Tex]W_{hx}[/Tex] and[Tex]W_{yh}[/Tex] represents the weight matrices[Tex]h_{t-1} [/Tex] represents hidden state from the previous time step (t-1)[Tex]\sigma[/Tex] represents the sigmoid activation function.[Tex]y_t [/Tex] represents output at time step t
Although vanilla RNNs can map sequences to sequences they suffer from the vanishing gradient problem. To address this advanced versions of RNNs like LSTM or GRU are used in Seq2Seq models as they can capture long-range dependencies more effectively.
How Does the Seq2Seq Model Work?
A Sequence-to-Sequence (Seq2Seq) model consists of two primary phases: encoding the input sequence and decoding it into an output sequence.
1. Encoding the Input Sequence
The encoder processes the input sequence token by token, updating its internal state at each step. After the entire sequence is processed, the encoder produces a context vector , a fixed-length representation that summarizes the important information from the input.
2. Decoding the Output Sequence
The decoder takes the context vector as input and generates the output sequence one token at a time. For example, in machine translation, it can convert the sentence “I am learning” into “Je suis apprenant” sequentially, predicting each token based on the context and previously generated tokens.
3. Teacher Forcing
During training, teacher forcing is commonly used. Instead of feeding the decoder’s own previous prediction as the next input, the actual target token from the training data is provided. This technique accelerates learning and helps the model produce more accurate sequences.
Applications of Seq2Seq Models
- Machine Translation: Translates text between languages.
- Text Summarization: Summarizes news articles and documents.
- Speech Recognition: Converts speech to text, especially with attention mechanisms.
- Image Captioning: Generates human-readable captions for images by integrating image features with text generation.
Advantages of Seq2Seq Models
- Flexibility: Can handle tasks like machine translation, text summarization and image captioning with variable-length sequences.
- Handling Sequential Data: Ideal for sequential data like natural language, speech and time series.
- Context Awareness: Encoder-decoder architecture captures the context of the input sequence to generate relevant outputs.
- Attention Mechanism: Focuses on key parts of the input sequence, improving performance, especially for long inputs.
Disadvantages of Seq2Seq Models
- Computationally Expensive: Requires significant resources to train and optimize.
- Limited Interpretability: Hard to understand the model's decision-making process.
- Overfitting: Prone to overfitting without proper regularization.
- Rare Word Handling: Struggles with rare words not seen during training.

