地理 空間 情報 を扱 うなら知 っておきたいPythonライブラリ、GeoPandas入門 ~基礎 編 ~
さまざまなデータを
Pythonで
しかし、このデータに
この
- ・ラスターデータとベクターデータの
振 り返 り - ・GeoPandasを
利用 してベクターデータの読 み込 みや描画 - ・csvデータとベクターデータの
組 み合 わせによる解析 - ・やや
高度 な描画 方法 - ・
時 系列 動画 (タイムラプス動画 )の作成 - ・Plotlyを
用 いた可視 化 例
について
ラスターとベクター
※
ラスターデータ

ラスターデータとは
この
ラスターはGeoPandasで

ラスターデータは

ピクセル
ベクターデータ
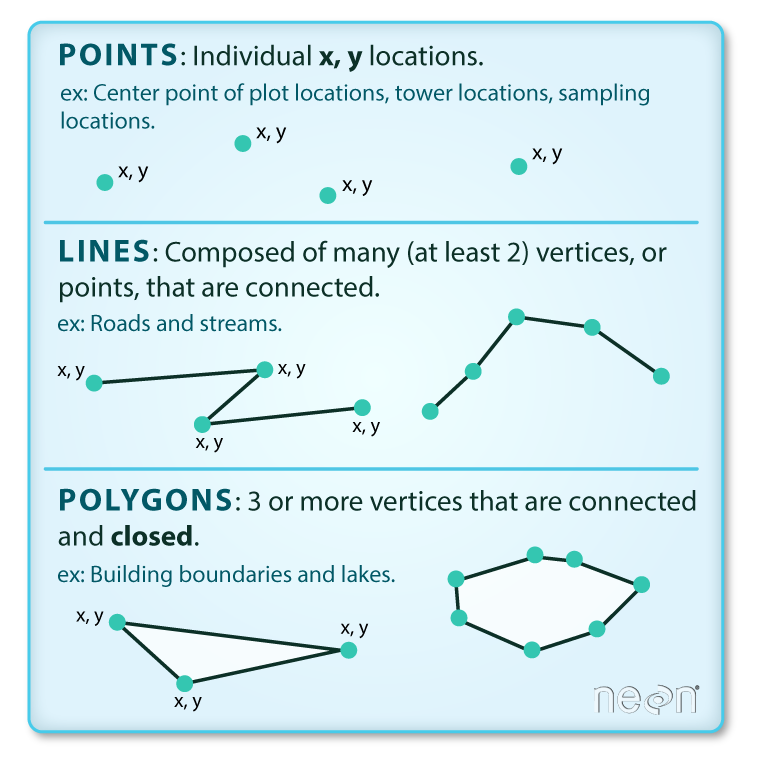
ベクターファイルの
GeoPandasを触 ってみよう
GeoPandasとはそもそも
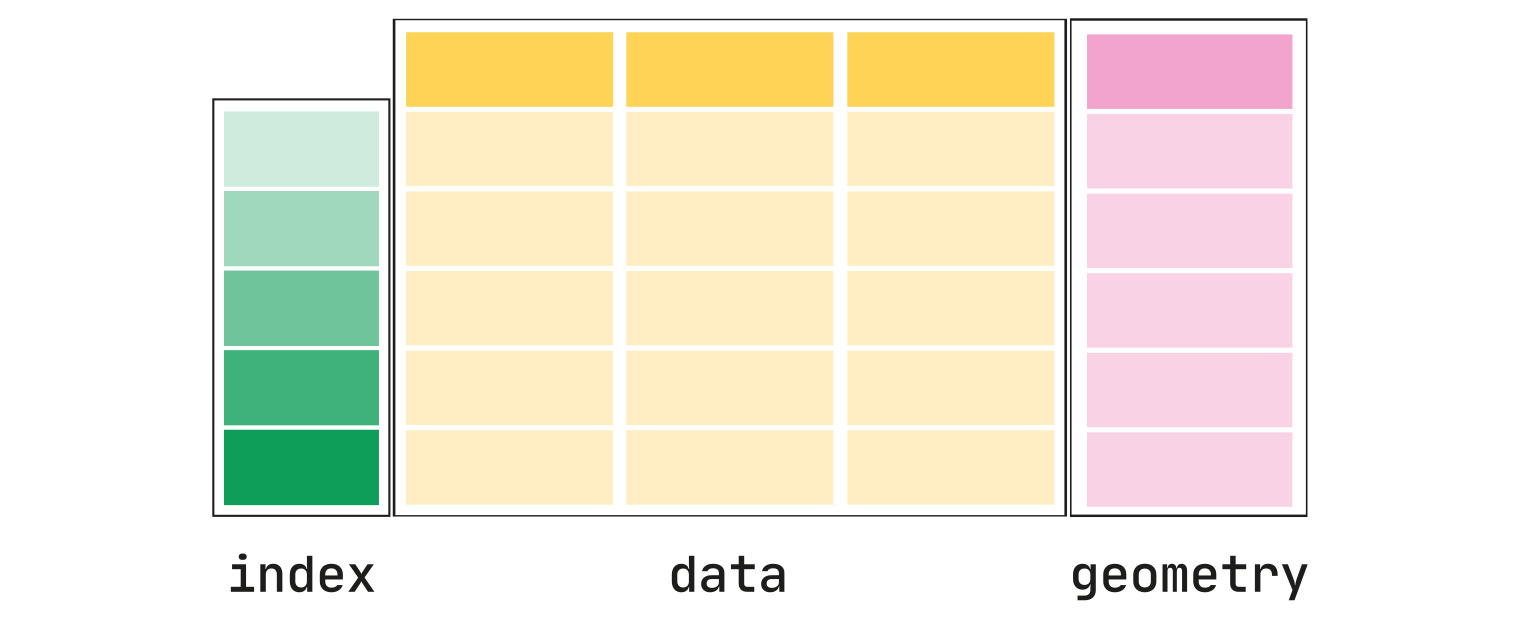
geomtryでは
- ・PointsまたはMulti-Points
- ・LinesまたはMulti-Lines
- ・PolygonsまたはMulti-Polygons
が
ColabでGeoPandas+
GeoPandasには
- ・numpy
- ・pandas
- ・shapely
- ・fiona
- ・pyproj
# Important library for many geopython libraries
!apt install gdal-bin python-gdal python3-gdal
# Install rtree - Geopandas requirment
!apt install python3-rtree
# Install Geopandas
!pip install git+git://github.com/geopandas/geopandas.git
# Install Folium for Geographic data visualization
# !pip install folium
!pip install plotly-express
!pip install --upgrade plotly
!pip install matplotlib-scalebar
# Use EE in Python
!pip install geemap
!pip install ipygee# Colab使用 時
import os
os.kill(os.getpid(), 9)# Colab使用 時
# Driveのマウント
# Filesからもワンクリックでマウント可能 です
from google.colab import drive
drive.mount('/content/drive')ライブラリのインポートを
import pandas as pd
import numpy as np
import os
import geopandas as gpd
from shapely.geometry import Point
import matplotlib
import matplotlib.pyplot as plt
import folium
import plotly_express as px
from datetime import datetime
import geemap
from ipygee import*データを
レイアウトをいじってからダウンロードしてありますが、それ
初婚 年齢 データの読 み込 み
# 階層 は適宜 変更 してください
marriageDf = pd.read_csv('/content/drive/MyDrive/Sorabatake/marriage.csv')データの
marriageDf.info()RangeIndex: 680 entries, 0 to 679
Data columns (total 14 columns):
# Column Non-Null Count Dtype
— —— ————– —–
0 cat01_code 680 non-null int64
1
2 cat02_code 680 non-null int64
3
4 cat03_code 680 non-null int64
5
6 cat04_code 680 non-null int64
7
8 area_code 680 non-null int64
9
10 time_code 680 non-null int64
11
12 unit 680 non-null object
13 value 680 non-null float64
dtypes: float64(1), int64(6), object(7)
memory usage: 74.5+ KB
こちらはe-statからダウンロードしたものとなります。ダウンロード
ここでは、
marriageDf.head()
marriageDf.describe(include='all')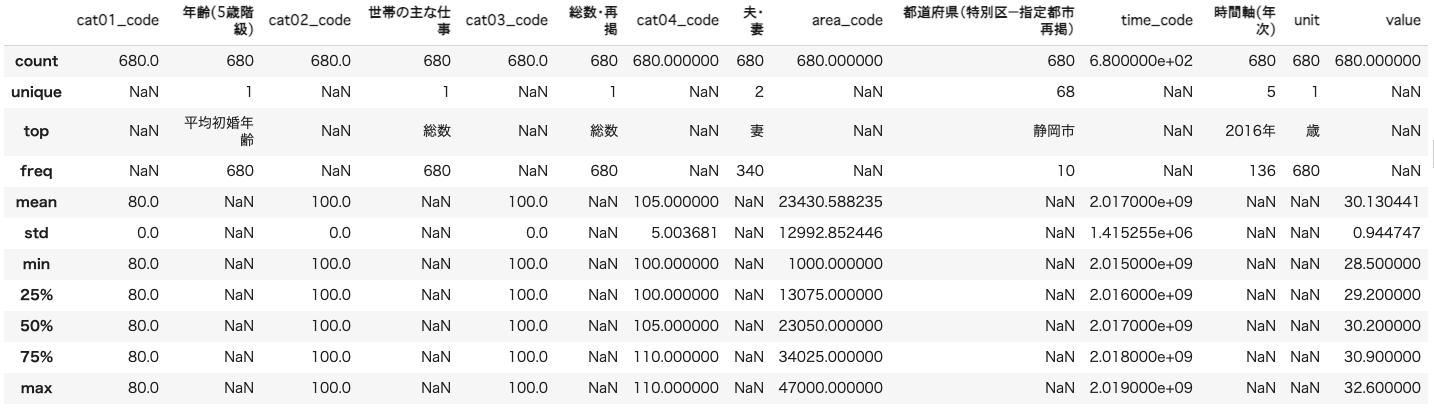
marriageDf = marriageDf.loc[:,['夫 ・妻 ','都道府県 (特別 区 −指定 都市 再掲 )','時間 軸 (年次 )','value']].\
rename(columns={'夫 ・妻 ':'sex','都道府県 (特別 区 −指定 都市 再掲 )':'prefecture','時間 軸 (年次 )':'year','value':'avgAge'}).copy()- ・
夫 はmale、妻 はfemale - ・xxxx
年 から年 を削除 - ・
都道府県 レベルのみ抽出
します。
marriageDf.sex = marriageDf.sex.replace('夫 ','male',regex=False).replace('妻 ','female',regex=False)
marriageDf.year = marriageDf.year.replace('年 $','',regex=True)
# marriageDf.year = pd.to_datetime(marriageDf.year, format = '%Y').dt.to_period('y')
marriageDf.year = marriageDf.year.astype('int64')includeStr = ['県 $','道 $','都 $','府 $']
marriageDf = marriageDf.loc[marriageDf.prefecture.str.contains('|'.join(includeStr)),:].reset_index(drop=True)marriageDf.describe(include='all') # describe all variables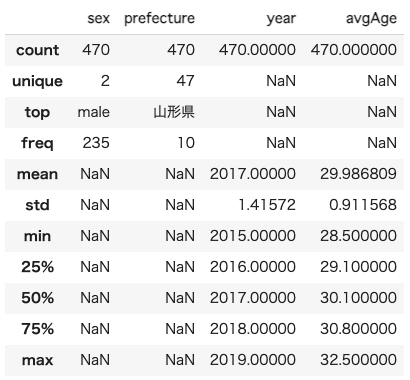
marriageDf.loc[marriageDf.avgAge == marriageDf.avgAge.min(),:]marriageDf.loc[marriageDf.avgAge == marriageDf.avgAge.max(),:]つまり、
ベクターファイルの読 み込 み
GADMからファイルをダウンロードします。
シェープファイルをダウンロードし、
- ・.cpg
- ・.dbf
- ・.prj
- ・.shp
- ・.shx
です。geopandasではシェープファイルを
# 階層 は適宜 変更 してください
jpnShp = gpd.read_file('/content/drive/MyDrive/Sorabatake/japanSHP/gadm36_JPN_1.shp')jpnShp.head()データフレーム
geopandasではフィルタリングもお
ax = jpnShp.plot(figsize=(10, 10))
jpnShp.plot(ax=ax)
plt.show();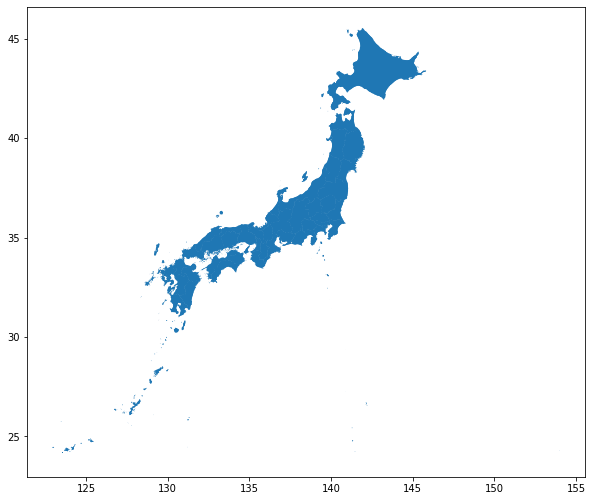
# 日本 のシェープデータを可視 化 する
ax = jpnShp.plot(figsize=(14, 14))
jpnShp.apply(lambda x: ax.annotate(s=x.NAME_1, xy=x.geometry.centroid.coords[0], ha='center', color = 'black', size = 6),axis=1)
jpnShp.plot(ax = ax, edgecolors='black')
plt.title('Administrative level 1 map in Japan', fontsize=16)
plt.show();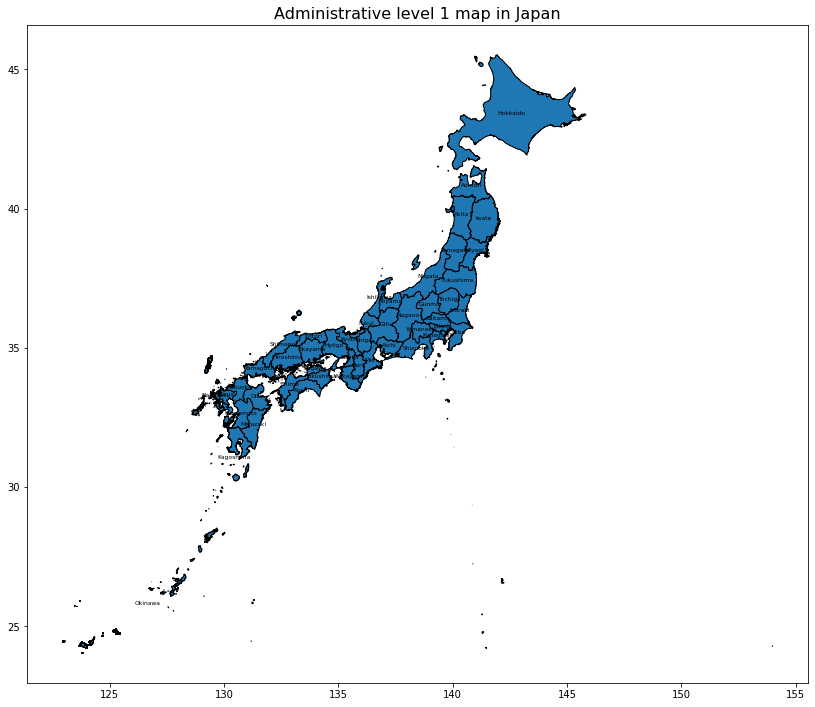
GeoDataFramedではShapelyとmatplotlibにより、
shpとcsvの結合
シェープファイルのようなデータは、
# 不 必要 な列 の削除
japan = jpnShp.loc[:,['NAME_1','NL_NAME_1','geometry']].copy()combDf = japan.merge(marriageDf,left_on='NL_NAME_1',right_on='prefecture',how='left') # データの結合
combDf.head() # checkfrom matplotlib_scalebar.scalebar import ScaleBar
from mpl_toolkits.axes_grid1 import make_axes_locatablePythonで
※
ScaleBarでは1ピクセルあたりの
# 男性
# 方位 の作成 についての参考 記事 :
## https://mohammadimranhasan.com/geospatial-data-mapping-with-python/
combDf2019M = combDf.loc[(combDf.year == 2019)&(combDf.sex == 'male'),:].reset_index(drop=True).copy()
ax = combDf2019M.plot(figsize=(16, 16))
scalebar = ScaleBar(50, location='lower right',units='km')
ax.add_artist(scalebar) # 200km
ax.text(x=153.215-0.55, y=40.4, s='N', fontsize=30) # North Arrow
ax.arrow(153.215, 39.36, 0, 1, length_includes_head=True,
head_width=0.8, head_length=1.5, overhang=.1, facecolor='k') # North Arrow
combDf2019M.apply(lambda x: ax.annotate(s=x.NAME_1, xy=x.geometry.centroid.coords[0], ha='center', color = 'black', size = 6),axis=1)
combDf2019M.plot(column='avgAge', cmap = 'rainbow', edgecolors='black', ax = ax, legend=True,legend_kwds={'label': "Average age of first marriage",'orientation': "vertical"})
plt.title('Average Age of First Marriage among Males by Prefectures in 2019', fontsize=16)
plt.show();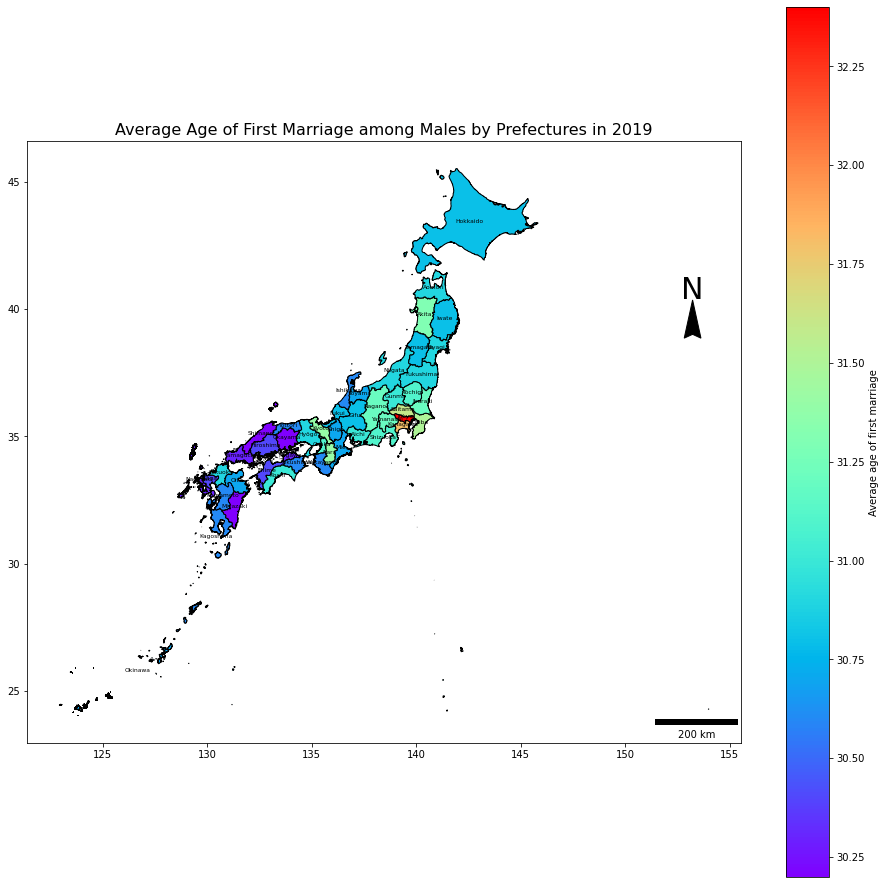
このように、
# 女性
combDf2019F = combDf.loc[(combDf.year == 2019)&(combDf.sex == 'female'),:].reset_index(drop=True).copy()
ax = combDf2019F.plot(figsize=(16, 16))
scalebar = ScaleBar(50, location='lower right',units='km')
ax.add_artist(scalebar) # 200km
ax.text(x=153.215-0.55, y=40.4, s='N', fontsize=30) # North Arrow
ax.arrow(153.215, 39.36, 0, 1, length_includes_head=True,
head_width=0.8, head_length=1.5, overhang=.1, facecolor='k') # North Arrow
combDf2019F.apply(lambda x: ax.annotate(s=x.NAME_1, xy=x.geometry.centroid.coords[0], ha='center', color = 'black', size = 6),axis=1)
combDf2019M.plot(column='avgAge', cmap = 'rainbow', edgecolors='black', ax = ax, legend=True,legend_kwds={'label': "Average age of first marriage",'orientation': "vertical"})
plt.title('Average Age of First Marriage among Females by Prefectures in 2019', fontsize=16)
plt.show();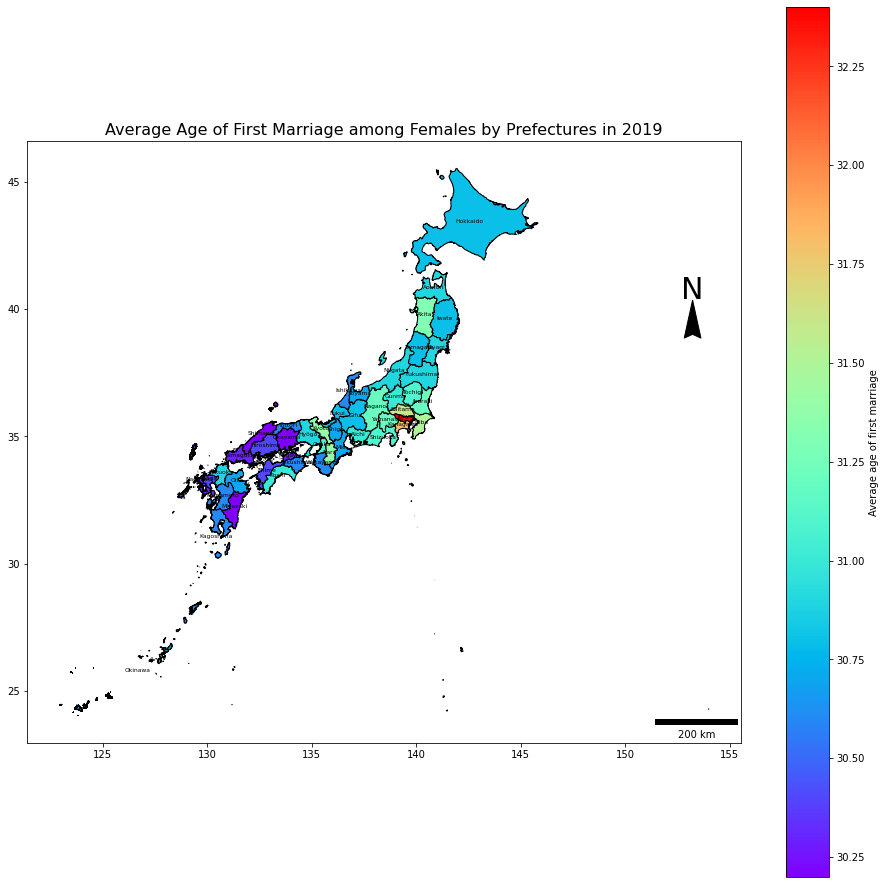
これらの
5
combDf2018M = combDf.loc[(combDf.year == 2018)&(combDf.sex == 'male'),:].reset_index(drop=True).copy()
combDf2017M = combDf.loc[(combDf.year == 2017)&(combDf.sex == 'male'),:].reset_index(drop=True).copy()
combDf2016M = combDf.loc[(combDf.year == 2016)&(combDf.sex == 'male'),:].reset_index(drop=True).copy()
combDf2015M = combDf.loc[(combDf.year == 2015)&(combDf.sex == 'male'),:].reset_index(drop=True).copy()with plt.rc_context(rc={'font.family': 'serif', 'font.weight': 'bold', 'font.size': 12}):
fig, ((ax1, ax2), (ax3, ax4), (ax5, ax6)) = plt.subplots(nrows=3, ncols=2, figsize = (20,20))
fig.autofmt_xdate(rotation = 45)
# 2019
scalebar = ScaleBar(50, location='lower right',units='km')
combDf2019M.plot(column='avgAge', cmap = 'rainbow', edgecolors='black', ax = ax1, legend=True,vmin=28.5, vmax=32.5)
ax1.set_title('Average age of first marriage in 2019', fontsize=10)
ax1.text(x=152.215-0.85, y=40.7, s='N', fontsize=15) # North Arrow
ax1.arrow(152.215, 39.36, 0, 1, length_includes_head=True, head_width=0.8, head_length=1.5, overhang=.1, facecolor='k') # North Arrow
ax1.add_artist(scalebar)
# 2018
scalebar = ScaleBar(50, location='lower right',units='km')
combDf2018M.plot(column='avgAge', cmap = 'rainbow', edgecolors='black', ax = ax2, legend=True,vmin=28.5, vmax=32.5)
ax2.set_title('Average age of first marriage in 2018', fontsize=10)
ax2.text(x=152.215-0.85, y=40.7, s='N', fontsize=15) # North Arrow
ax2.arrow(152.215, 39.36, 0, 1, length_includes_head=True, head_width=0.8, head_length=1.5, overhang=.1, facecolor='k') # North Arrow
ax2.add_artist(scalebar)
# 2017
scalebar = ScaleBar(50, location='lower right',units='km')
combDf2017M.plot(column='avgAge', cmap = 'rainbow', edgecolors='black', ax = ax3, legend=True, vmin=28.5, vmax=32.5)
ax3.set_title('Average age of first marriage in 2017', fontsize=10)
ax3.text(x=152.215-0.85, y=40.7, s='N', fontsize=15) # North Arrow
ax3.arrow(152.215, 39.36, 0, 1, length_includes_head=True, head_width=0.8, head_length=1.5, overhang=.1, facecolor='k') # North Arrow
ax3.add_artist(scalebar)
# 2016
scalebar = ScaleBar(50, location='lower right',units='km')
combDf2016M.plot(column='avgAge', cmap = 'rainbow', edgecolors='black', ax = ax4, legend=True, vmin=28.5, vmax=32.5)
ax4.set_title('Average age of first marriage in 2016', fontsize=10)
ax4.text(x=152.215-0.85, y=40.7, s='N', fontsize=15) # North Arrow
ax4.arrow(152.215, 39.36, 0, 1, length_includes_head=True, head_width=0.8, head_length=1.5, overhang=.1, facecolor='k') # North Arrow
ax4.add_artist(scalebar)
# 2015
scalebar = ScaleBar(50, location='lower right',units='km')
combDf2015M.plot(column='avgAge', cmap = 'rainbow', edgecolors='black', ax = ax5, legend=True, vmin=28.5, vmax=32.5)
ax5.set_title('Average age of first marriage in 2015', fontsize=10)
ax5.text(x=152.215-0.85, y=40.7, s='N', fontsize=15) # North Arrow
ax5.arrow(152.215, 39.36, 0, 1, length_includes_head=True, head_width=0.8, head_length=1.5, overhang=.1, facecolor='k') # North Arrow
ax5.add_artist(scalebar)
# Blank
ax6.axis('off')
# plt.tight_layout(pad=4)
plt.show();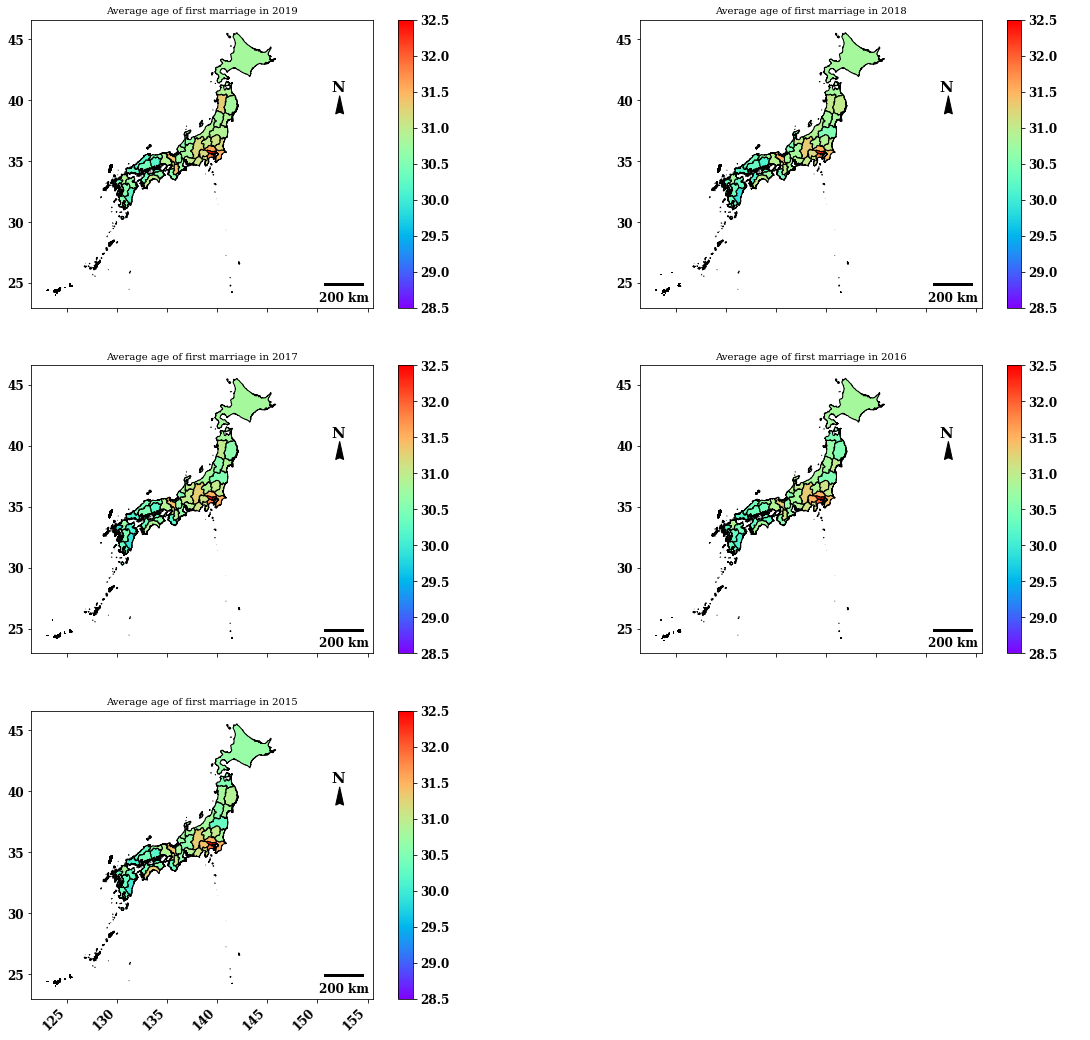
2015〜2019の5
ffmpegを
maleDf = combDf.loc[combDf.sex == 'male',:] # Extract males' values
dateMin = maleDf['year'].min()
n_years = maleDf['year'].nunique()# 画像 とアニメーションの参考 記事
## https://qiita.com/croquette0212/items/8ff251d5da77e803c253
## https://medium.com/tech-carnot/time-lapse-choropleth-map-visualization-using-geopandas-8adb77a7d14
for i in range(0,n_years):
nyear = dateMin + i
#Get cumulative df till that date
dfYear = maleDf.loc[maleDf['year'] == nyear,:]
fig, ax = plt.subplots(1, figsize=(10,8))
dfYear.plot(column='avgAge',
cmap='Blues', linewidth=0.8, ax=ax, edgecolor='0.8')
# remove the axis
ax.axis('off')
# add a title
ax.set_title('Average Age of First Marriage among Males',
fontdict={'fontsize': '25', 'fontweight' : '3'})
# Create colorbar as a legend
sm = plt.cm.ScalarMappable(cmap='rainbow',
norm=plt.Normalize(vmin=dfYear['avgAge'].min(), vmax=dfYear['avgAge'].max()))
# add the colorbar to the figure
cbar = fig.colorbar(sm)
fontsize = 20
# Positions for the date
date_x = 140
date_y = 30
syear = str(nyear)
ax.text(date_x, date_y,
f"{syear}",
color='black',
fontsize=fontsize)
fig.savefig(f"/content/drive/MyDrive/Sorabatake/videoff/frame_{i:03d}.png",
dpi=100, bbox_inches='tight')
plt.close()このffmpegで
imgDir = '/content/drive/MyDrive/Sorabatake/videoff' # 動画 の保存 場所
if not os.path.exists(imgDir):
os.makedirs(imgDir) # フォルダ作成
# 同 じ動画 名 にならないように注意
!ffmpeg -framerate 1 -i "$imgDir/frame_%03d.png" -c:v h264 -r 30 "$imgDir/avgAgevideo.mp4"
Plotlyを使 う
fig = px.choropleth(combDf, # データフレーム
locations="NAME_1", # 場所 の名称 を取得
color="avgAge", # 色付 けするデータ指定
hover_name="NAME_1", # マウスホバーで表示 するデータ
animation_frame="year", # 時間 データ指定
projection="natural earth", # 投影 する面 指定
color_continuous_scale = 'Peach', # 色 指定
range_color=[28,33] # 色付 けするデータの範囲 を指定
)
fig.update_geos(
center=dict(lon=136, lat=37), scope='asia',
lataxis_range=[28,47], lonaxis_range=[125, 150]
)
fig.show()
# plt.close(fig)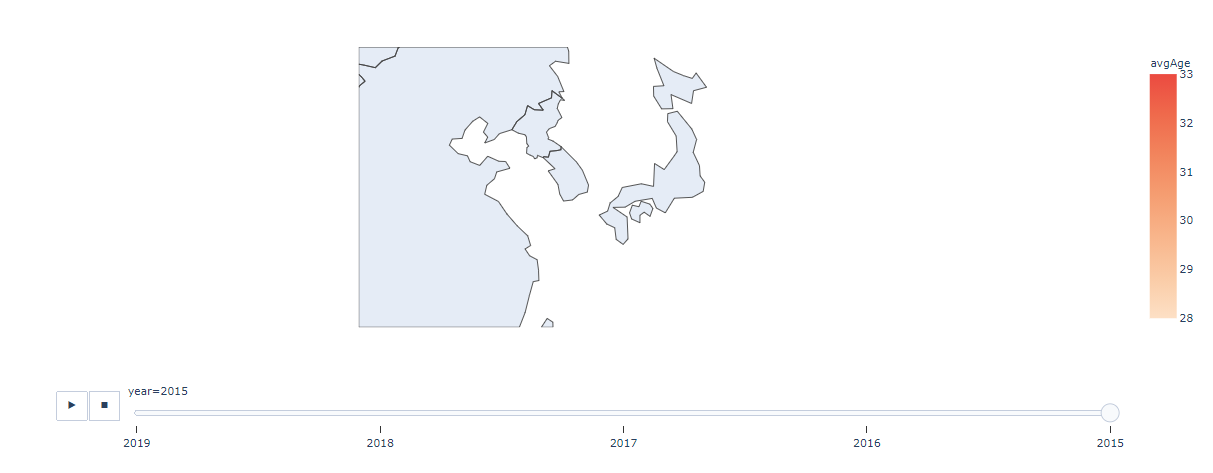
と
こちらの
df2019 = combDf.loc[combDf.year == 2019,:]
fig = px.treemap(df2019, path=['prefecture'], values='avgAge', color='avgAge', color_continuous_scale='magma')
fig.show()
import plotly.graph_objects as go
from plotly.subplots import make_subplotsdf2018 = combDf.loc[combDf.year == 2018,:]
df2017 = combDf.loc[combDf.year == 2017,:]
df2016 = combDf.loc[combDf.year == 2016,:]
df2015 = combDf.loc[combDf.year == 2015,:]fig = make_subplots(
cols = 2, rows = 3,
column_widths=[0.5, 0.5],
specs = [[{'type': 'treemap'}, {'type': 'treemap'}],
[{'type': 'treemap'}, {'type': 'treemap'}],
[{'type': 'treemap'}, {'type': 'treemap'}]],
horizontal_spacing = 0.01,
vertical_spacing = 0.01
)
fig.add_trace(go.Treemap(
labels = df2019['prefecture'].values,
parents = df2019['year'].values,
values = df2019['avgAge'].values,
marker=dict(
colors=df2018['avgAge'],
colorscale='magma'),
textinfo = "label+value",
),row = 1, col = 1)
fig.add_trace(go.Treemap(
labels = df2018['prefecture'].values,
parents = df2018['year'].values,
values = df2018['avgAge'].values,
marker=dict(
colors=df2018['avgAge'],
colorscale='magma'),
textinfo = "label+value",
),row = 1, col = 2)
fig.add_trace(go.Treemap(
labels = df2017['prefecture'].values,
parents = df2017['year'].values,
values = df2017['avgAge'].values,
marker=dict(
colors=df2017['avgAge'],
colorscale='magma'),
textinfo = "label+value",
),row = 2, col = 1)
fig.add_trace(go.Treemap(
labels = df2016['prefecture'].values,
parents = df2016['year'].values,
values = df2016['avgAge'].values,
marker=dict(
colors=df2016['avgAge'],
colorscale='magma'),
textinfo = "label+value",
),row = 2, col = 2)
fig.add_trace(go.Treemap(
labels = df2015['prefecture'].values,
parents = df2015['year'].values,
values = df2015['avgAge'].values,
marker=dict(
colors=df2015['avgAge'],
colorscale='magma'),
textinfo = "label+value",
),row = 3, col = 1)
fig.update_layout(height = 1400, width = 1400, paper_bgcolor="LightSteelBlue")
fig.show()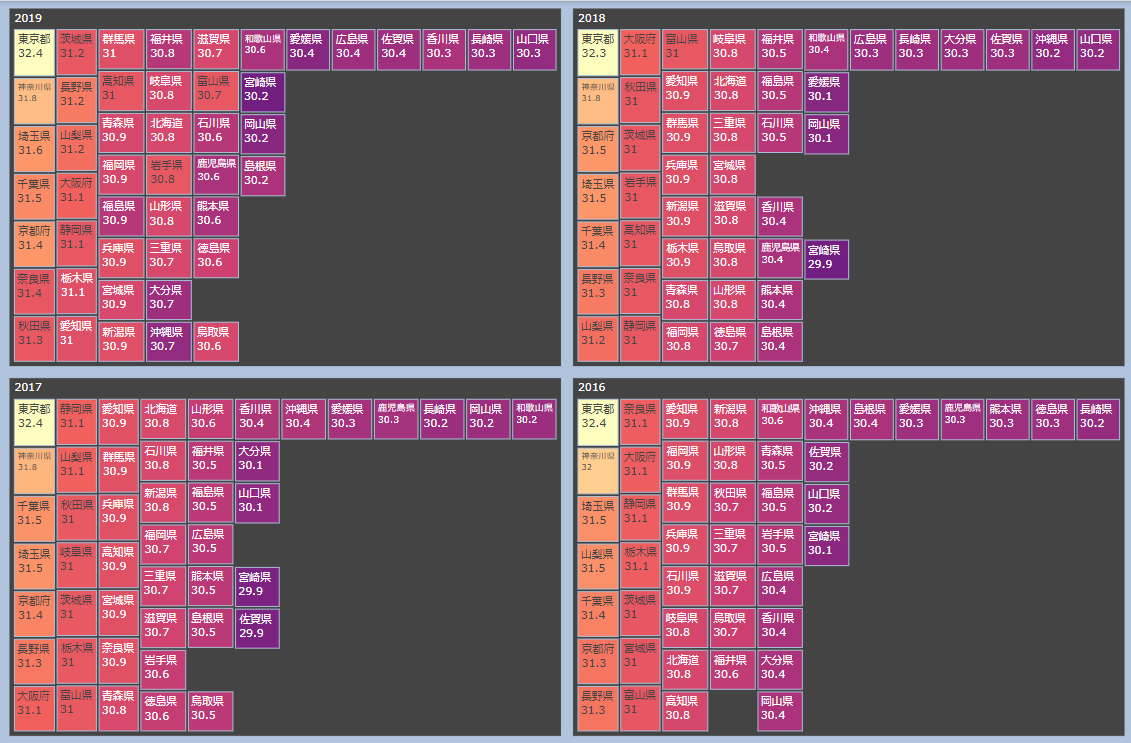

汎用 的 な参考 文献
PythonとGIS
ライブラリ
Rでの
