 KnowEdit
KnowEdit
A Comprehensive Study of Knowledge Editing for Large Language Models
🔔News
[2024-11-19]: We update the Table 4 results in the paper "A Comprehensive Study of Knowledge Editing for Large Language Models" after optimizing certain methods (related to AdaLoRA) and fixing computational bugs (related to ROME and MEMIT) in the EasyEdit. These improvements have led to better results than before.
We further add several new literatures on knowledge mechanism, steering, memory, and AI safety, and discuss the current status of this field. We will continue updating this paper and welcome everyone to discuss and exchange ideas :)
[2024-01-03]: We release a new paper: "A Comprehensive Study of Knowledge Editing for Large Language Models" with a new benchmark KnowEdit!
Abstract
Large Language Models (LLMs) have shown extraordinary capabilities in understanding and generating text that closely mirrors human communication. However, a primary limitation lies in the significant computational demands during training, arising from their extensive parameterization. This challenge is further intensified by the dynamic nature of the world, necessitating frequent updates to LLMs to correct outdated information or integrate new knowledge, thereby ensuring their continued relevance. Note that many applications demand continual model adjustments post-training to address deficiencies or undesirable behaviors. There is an increasing interest in efficient, lightweight methods for on-the-fly model modifications. To this end, recent years have seen a burgeoning in the techniques of knowledge editing for LLMs, which aim to efficiently modify LLMs' behaviors within specific domains while preserving overall performance across various inputs. In this paper, we first define the knowledge editing problem and then provide a comprehensive review of cutting-edge approaches. Drawing inspiration from educational and cognitive research theories, we propose a unified categorization criterion that classifies knowledge editing methods into three groups: resorting to external knowledge, merging knowledge into the model, and editing intrinsic knowledge. Furthermore, we introduce a new benchmark, KnowEdit, for a comprehensive empirical evaluation of representative knowledge editing approaches. Additionally, we provide an in-depth analysis of knowledge location, which can give a deeper understanding of the knowledge structures inherent within LLMs. Finally, we discuss several potential applications of knowledge editing, outlining its broad and impactful implications.
Knowledge Editing for LLMs
Task Definition
The initial goal of knowledge editing is to modify the specific knowledge
Suppose the original model is
The post-edited model
As a knowledge base, it's paramount that knowledge editing cater to three fundamental settings: knowledge insertion, knowledge modification, and knowledge erasure.
In conclusion, the interplay between knowledge insertion, modification, and erasure forms essential aspects of model editing techniques. When combined, these techniques empower LLMs to transform, self-correct, and ethically adapt as needed.
Method
The development of LLMs has reached a point where their capabilities closely resemble human cognitive processes, especially in learning and acquiring knowledge. Drawing inspiration from how humans learn, we can analogously apply these concepts to the process of editing LLMs as Figure shows below.
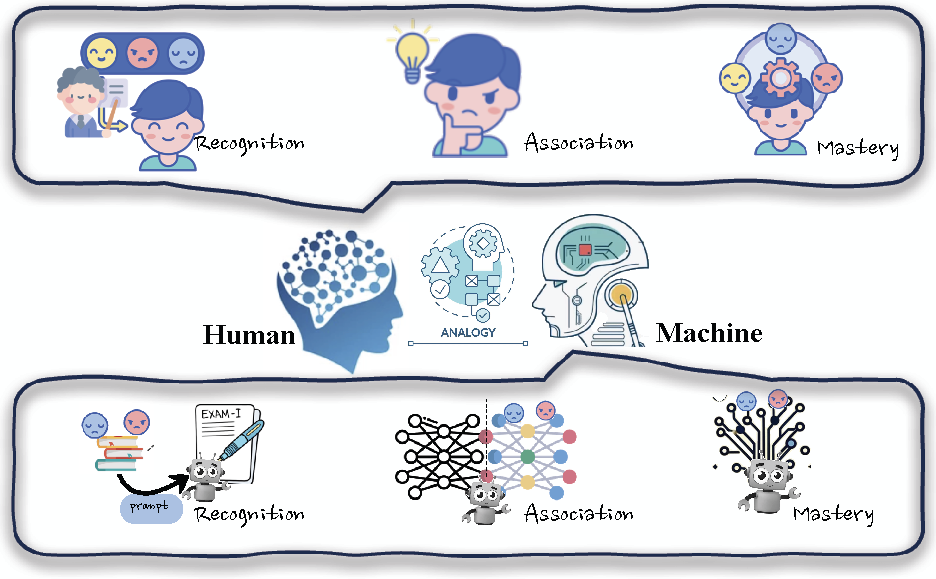
Applying Human Learning Phases to Knowledge Editing in LLMs: We see an analogy of Human Learning Phases and Knowledge Editing in LLMs and categorize current knowledge editing methods based on the learning phases of humans: recognition, association, and mastery.
Educational and cognitive research delineates human knowledge acquisition into three distinct phases: recognition, association, and mastery. These phases offer a framework for conceptualizing the methods of knowledge editing in LLMs and we list them in Table below.
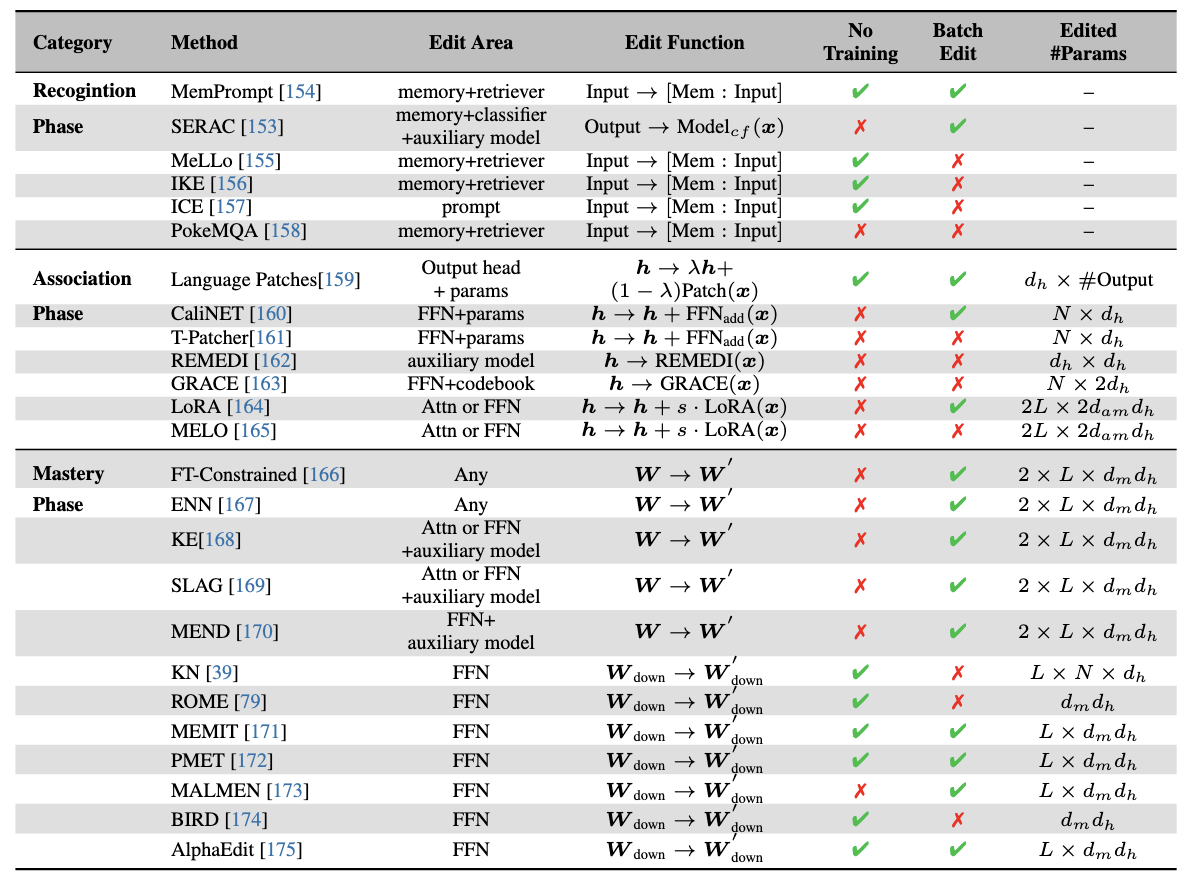
Comparison between representative approaches of knowledge editing for LLMs.
No Training refers to the methods that do not require additional training;
Batch Edit means whether the methods can support editing multiple cases simultaneously in just one process.
Edit Area refers to where the model's components are used;
Editor #Params indicates the parameters that need to be updated for editing.
New Benchmark: KnowEdit
To evaluate the effectiveness of knowledge editing methods, several datasets have been proposed. In this Section, we present an overview of the current datasets used for knowledge editing and introduce a new benchmark, KnowEdit, which serves as a comprehensive evaluation framework for various knowledge editing techniques.
For this study, we have curated a set of six datasets that are well-suited for assessing knowledge editing methods. A detailed statistical overview of these datasets is presented in Table below, and they encompass a range of editing types, including fact manipulation, sentiment modification, and hallucination generation.

Statistics on the benchmark KnowEdit, with six selected datasets for the evaluation of knowledge editing methods. We select different knowledge types for the insertion, modification, and erasure settings.
Evaluation for Knowledge Editing
Knowledge editing aims to alter model behavior based on modified facts. However, knowledge is interconnected; changing one fact may ripple outwards and affect other facts in complex ways. This interdependence makes assessing the effects of editing difficult. We summarize key evaluation criteria from prior work into four categories: edit success, portability, locality, and fluency.
Experiments
Experiment Settings
All the experiments are conducted by EasyEdit. As to the evaluation of the post-edited model, some of the previous works computed the probability difference of the output for pre-edit and post-edit models:
Also, for portability, we compute the post-edited model's performance on the given sets.
As to the calculation of locality, some work computes the post-edited model's performance on the locality set
Meanwhile, for the sentiment edit task Convsent, we compute the Edit Succ. and Locality as the original dataset:
Where
For the knowledge erasure task Sanitation, we calculate edit success as whether the model answers ``I don't know.'' for the given knowledge. As for the locality, we compute the performance on the retain sets as whether the model keeps their original answer.
Main Results
We list the results of current knowledge editing methods on Llama2-7b-chat in Table below.
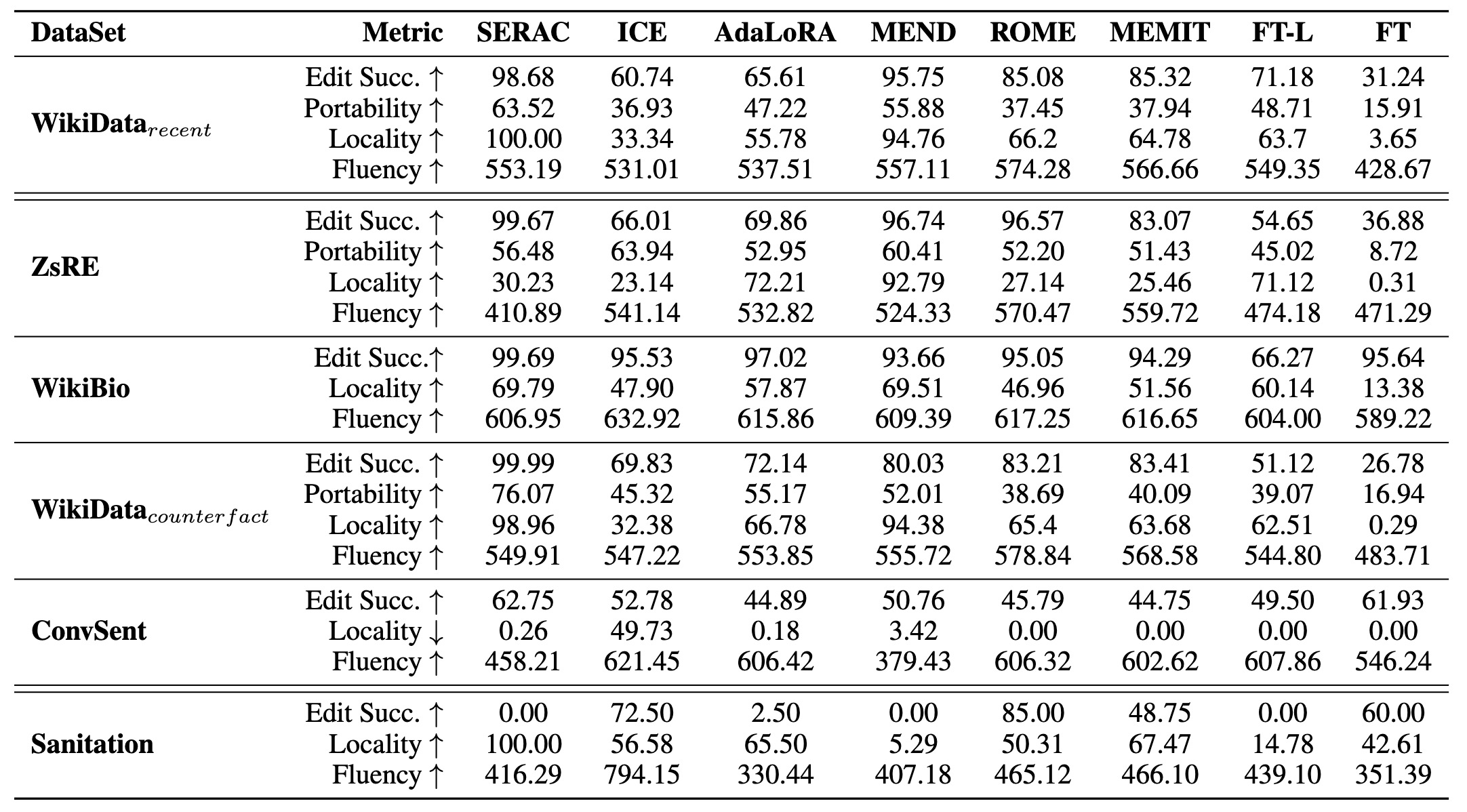
Results of existing knowledge edit methods on the constructed benchmark. The symbol
Impact of Knowledge Editing on General Tasks
In this Section, we explore the impact of applying knowledge editing methods on the performance of a language model across various domains. Our main goal is to determine if incorporating edits related to specific factual knowledge can unintentionally hinder the model's proficiency in unrelated areas.
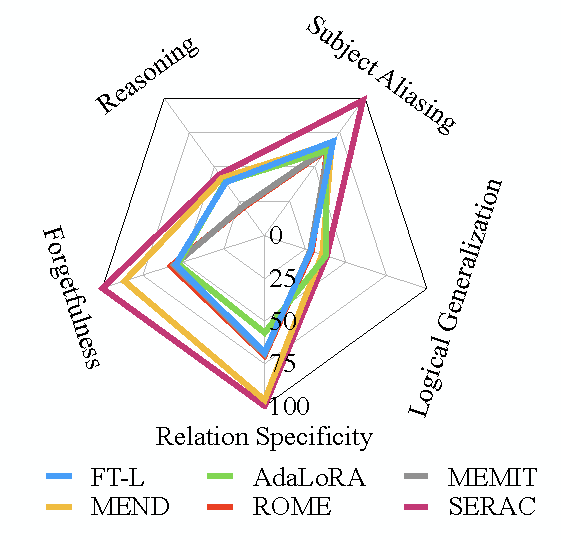
Average sub-metrics performance of results on several fact edit datasets in Portability and Locality.
When directly fine-tuning the entire model on the provided edited cases, a significant decline in the post-edited model's performance on general tasks is observed. We find that the post-edited model becomes inclined to generate outputs resembling the edited cases, which highlights the presence of overfitting. An intriguing observation from Table below is that, on a holistic level, the edited models managed to sustain a performance level that is close to their unedited counterparts.
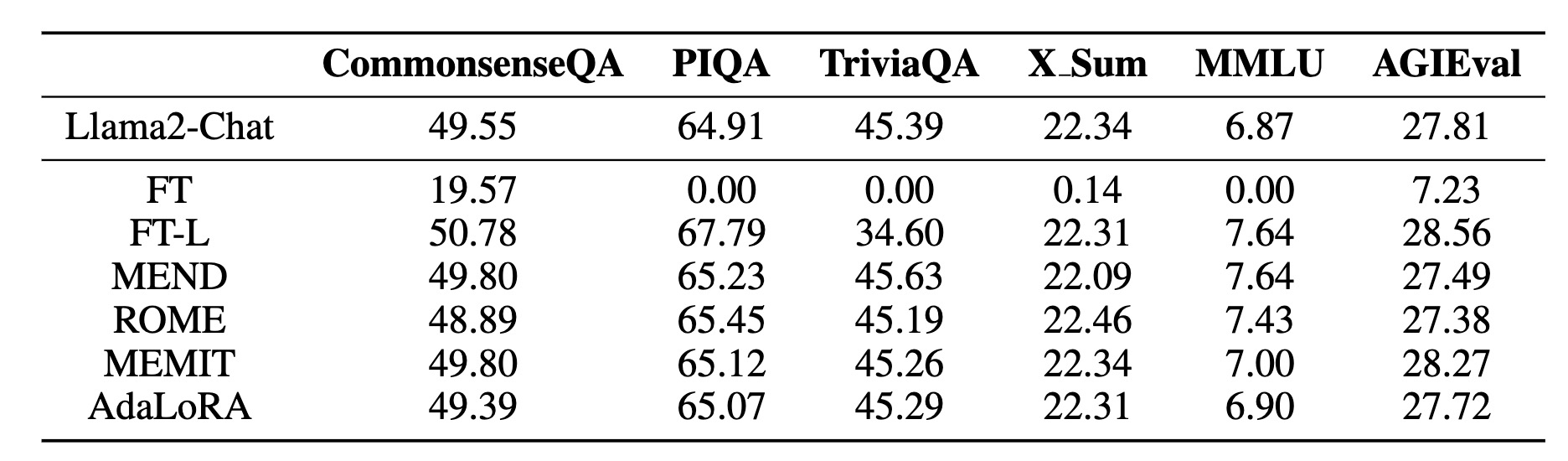
The zero-shot performance on the general LLM benchmark with Llama2-Chat-7B as the base model. Here, we conduct 5 consecutive edits for each method using the Wiki
This suggests that the negative impact of the editing was limited to directly altered topics. However, one exception to this trend is the FT-L model's performance on TriviaQA, which shows a noticeable decline from an initial score of 45.39 to 34.60 after the edit. Nevertheless, taking a broader perspective, we can observe commendable consistency. This implies that contemporary knowledge editing methods are effective in executing five targeted factual updates with minimal disruptions to the model's cognitive capabilities and adaptability across diverse knowledge domains.
Multi-Task Knowledge Editing
Previous work considered a sequential edit for a lifelong knowledge editing. However, they always conduct sequential editing on a single dataset from the same distribution. This is a bit different from Continuous learning. Knowledge editing is not a task focusing on single-domain knowledge or fact. In reality, we may want to modify our model from different perspectives from different distributions.
Cross-domain Editing
Both MEND and SERAC methods rely on a training dataset to help the model learn how to edit parameters. We evaluate their performance in a cross-domain setting and present the results in Table below.
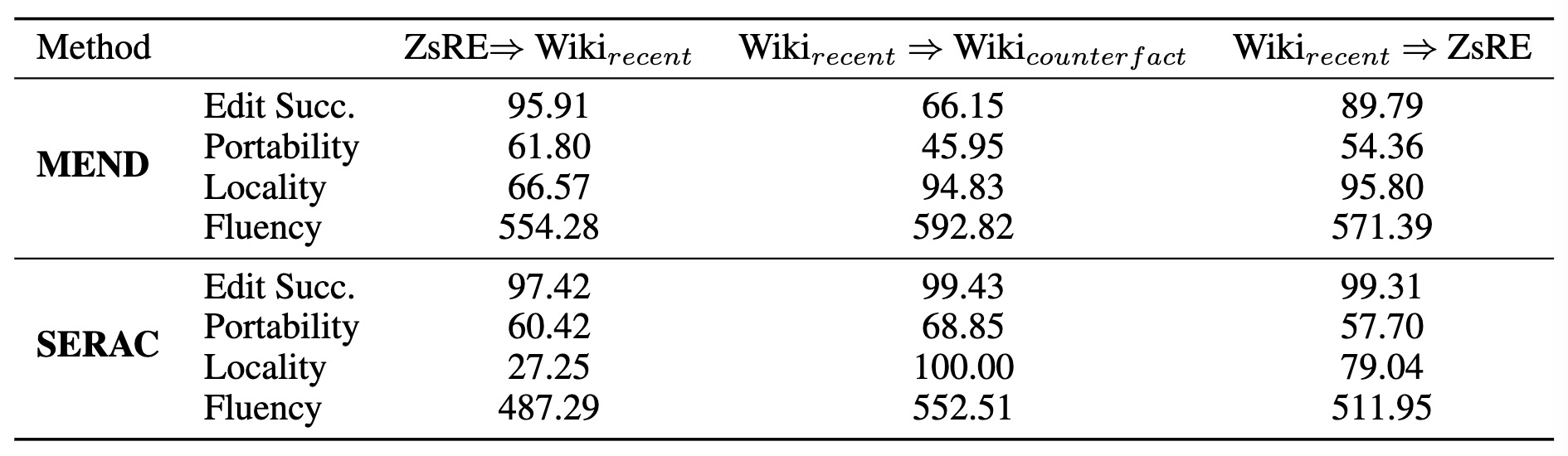
Cross-Domain Editing Results.
Performance (accuracy) of the compared methods, which are firstly trained on a source dataset and then directly conduct prediction on a target dataset (denoted as source
For the MEND method, the hyper-network trained using the ZsRE dataset exhibits better cross-domain performance than that trained with the recent dataset. This can be attributed to the enormous size of the ZsRE dataset, allowing MEND's hyper-network to enhance its parameter-editing capabilities. Meanwhile, the SERAC approach, by leveraging its cache, exhibits significant cross-domain editing prowess.
Continual Editing
Methods like LoRA and ROME do not require a training set and can be applied directly to different domains.
Hence, we consider a more challenging setting for continual editing.
We mix different knowledge editing cases using the ZsRE, Wiki
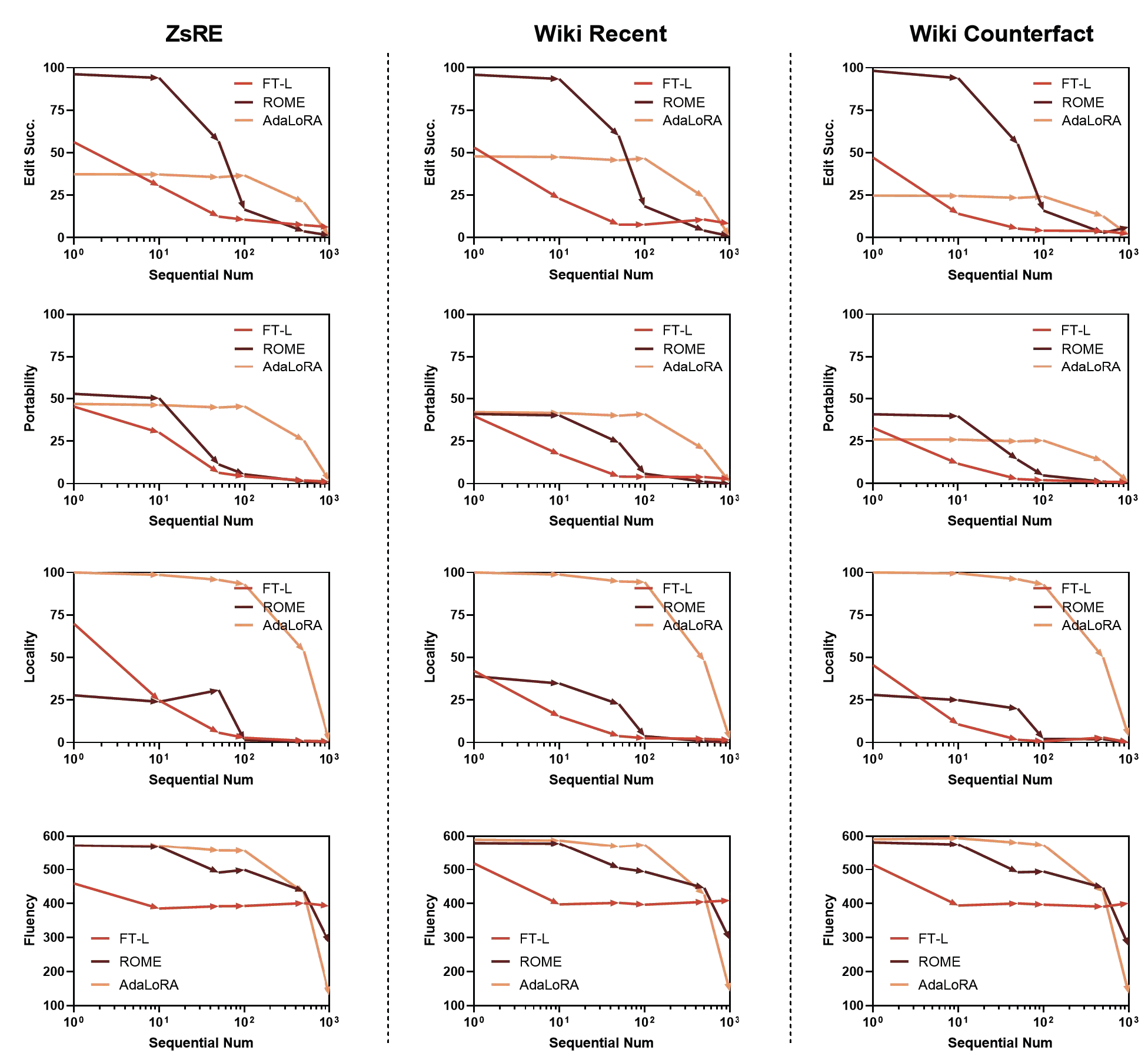
Sequential editing results in randomly selected data from WikiData
When dealing with sequential editing, we can observe that these three methods all suffer from 1,000 editing times with a dramatic drop in all evaluation metrics, and the trend is similar for three different tasks. Relatively, AdaLoRA shows a stable performance for about 100 edits. Current editing methods tend to edit the same area for different knowledge (e.g. ROME the fifth layer, MEND the last three layers), while the knowledge is not stored in this area.
Error and Case Analysis
As shown in the results, different methods demonstrate different performance on different tasks. Here, we conduct a study to comprehensively understand their limitations and advantages. In analyzing the failure modes of knowledge editing methods, we categorize the deficiencies into four primary types:
- Meaningless Token Generation: The edited model produces meaningless tokens such as `\n' or repetitive letter combinations that lack semantic meaning or grounding.
- Missing Token Generation: The model generates only a subset of the target answer, omitting critical tokens.
- Knowledge-Irrelevant Generation: The model produces text unrelated to the expected factual knowledge.
- Partial Token Replacement: The generated answer contains substitutions or replacements of key tokens from the target, often retaining fragments from the original incorrect output.
The occurrence of these error types helps identify the limitations of the editing methods. Meaningless and missing token cases highlight difficulties in fully encoding the target fact, while knowledge-irrelevant and partial replacement generations suggest that the edits fail to supplant previously learned information. We conduct an error analysis on the ZsRE tasks and counted the error cases for each editing method. The results are presented in Figure below.
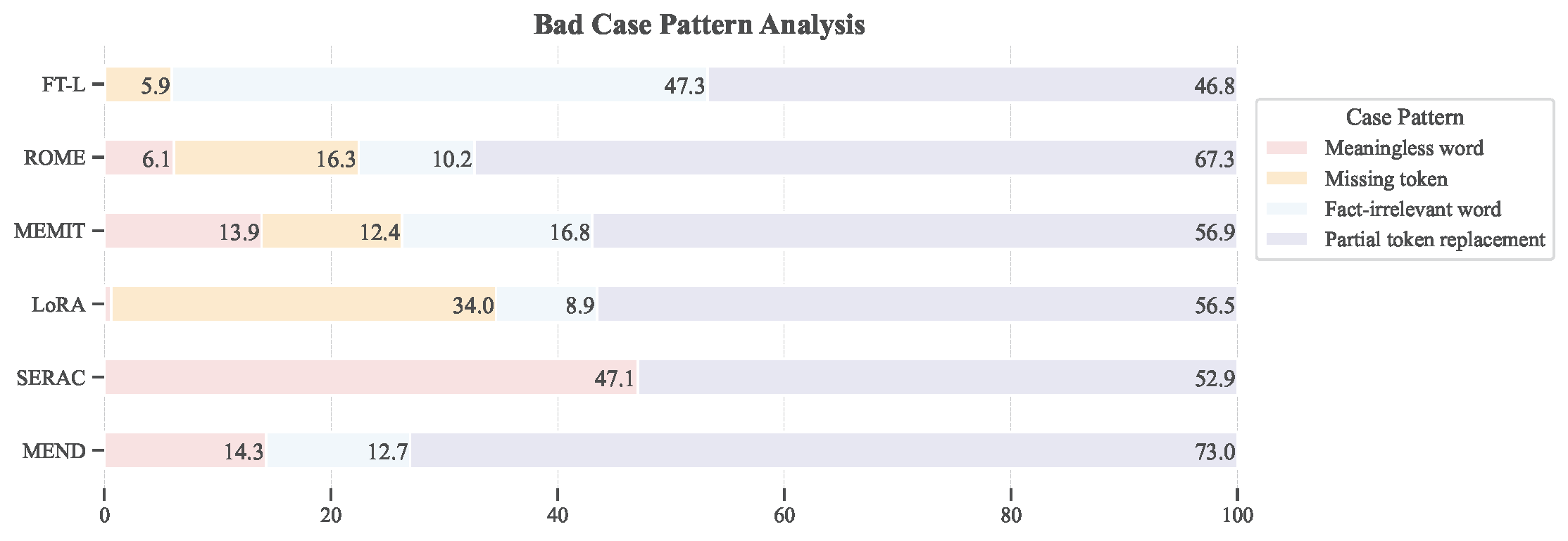
Bad cases statistics for different knowledge editing methods.
Here, we can find the main error type is the partial token replacement due to the conflict of the knowledge in the original model and our target one. The analysis reveals that the main error type is partial token replacement, indicating a conflict between the knowledge in the original model and the target knowledge. Specifically, the SERAC method tends to generate meaningless tokens due to the limited generation ability of the small model used. The AdaLoRA method may miss some tokens related to the target knowledge. For the fine-tuning methods, the percentage of fact-irrelevant words is higher compared to other editing methods, and it is the most common error type (47.3\%) for FT-L. This suggests that the objective of fine-tuning might not be suitable for editing specific knowledge. Additionally, in the following section, we find that FT-L tends to modify more areas in the parameters, leading to more irrelevant generations.
We also show the generated texts for different editing methods for the cases in Table below.

Results for one case of different editing methods. Prompts are presented in italicized text. Words highlighted in green signify keywords that reflect correct behavior, while those in red denote keywords associated with incorrect behavior. Texts in cyan are repeated or meaningless sentences.
Here, we can find that current editing methods, like IKE, MEND, ROME can successfully modify the material of the Queen Amina Statue from bronze to limestone and generate fluent texts. SERAC and FT-L, despite changing the facts successfully, tend to generate repeated sentences or meaningless entities. Additionally, AdaLoRA failed to change the fact and kept the original answer, "bronze".
Analysis
Current research has explored the effectiveness of knowledge editing methods in LLMs, but the underlying reasons for their superior performance remain unexplored. Additionally, the comparison between model editing and fine-tuning approaches, as well as the efficacy of knowledge location methods, requires further investigation. This study proposes a simple attempt to bridge these gaps by examining the differences between model editing and fine-tuning, exploring the effectiveness of knowledge location techniques, and understanding the knowledge structure within LLMs. We hope further investigation will unveil the mechanisms of knowledge in LLMs.
Comparison of Different Knowledge Editing Methods
The effectiveness of current knowledge editing methods is commendable, but the reasons behind their superior performance compared to other approaches remain elusive.
In this section, we focus on methods that involve parameter adjustments within the model, specifically MEND, ROME, MEMIT, and FT-L.
As these methods modify the model's parameters, a fundamental question arises: what makes some knowledge editing methods, like MEND, superior in terms of locality and overall performance?
We formally represent the change as
Sparsity
An important characteristic of knowledge editing is its intention to modify a specific piece of knowledge within the model. This suggests an intuitive hypothesis that the $\Delta \boldsymbol{W}$ matrix is likely to be sparse. Following the approach of De Cao et al. , we present visualizations that capture weight updates resulting from knowledge edits, as depicted in Figure below.
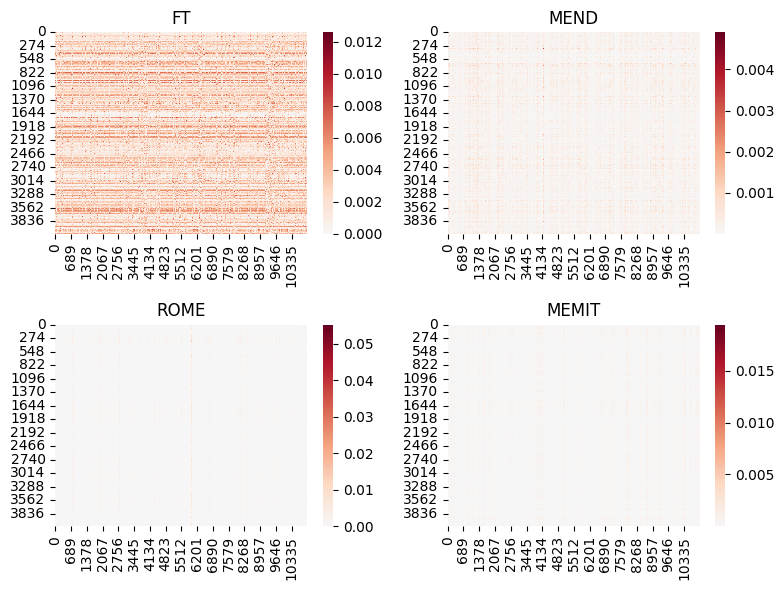
The heatmap shows how different model editing methods affect the weights of the model. Darker colors indicate more changes in the weights. The heatmap reveals which parts of the model are most sensitive to changes for each method.
ROME, MEND, and MEMIT exhibit a distinct pattern of sparse updates, while fine-tuning spreads its modifications more uniformly across weights. Particularly, for knowledge editing methods like ROME and MEMIT, it is intriguing to observe a concentrated focus on one or several columns of the value layer. This finding aligns with earlier research that emphasizes the value layer's pivotal role in encapsulating correlated knowledge. Regarding the MEND methods, we propose that the learned hypernetwork can be viewed as a tool or a "probe" that helps us explore and understand the internal mechanisms used by the model to encode knowledge, providing insights into how the model represents and processes information.
Mapping to Embedding Space
To further investigate the differences between different editing methods, we conduct an embedding space analysis following the approach of Dar et al. They analyze the Transformer's parameters by mapping the weights of the LLMs to the vocabulary space and find that the embedding space can interpret these weights. Here, we map the two matrices, $\boldsymbol{W}'$ and $\boldsymbol{W}$, to observe the differences between these methods. From the sparsity analysis, we select the top five columns of the updated value matrix $\Delta \boldsymbol{W}$ and map the corresponding columns of $\boldsymbol{W}'$ and $\boldsymbol{W}$ into the embedding matrices $\boldsymbol{E}$ to obtain the logits in the vocabulary space. We then compute the Hit@10 and Hit@50 of the new knowledge in the output logits. We select cases from ZsRE where all four methods successfully edit the knowledge and present the average performance in Figure below.
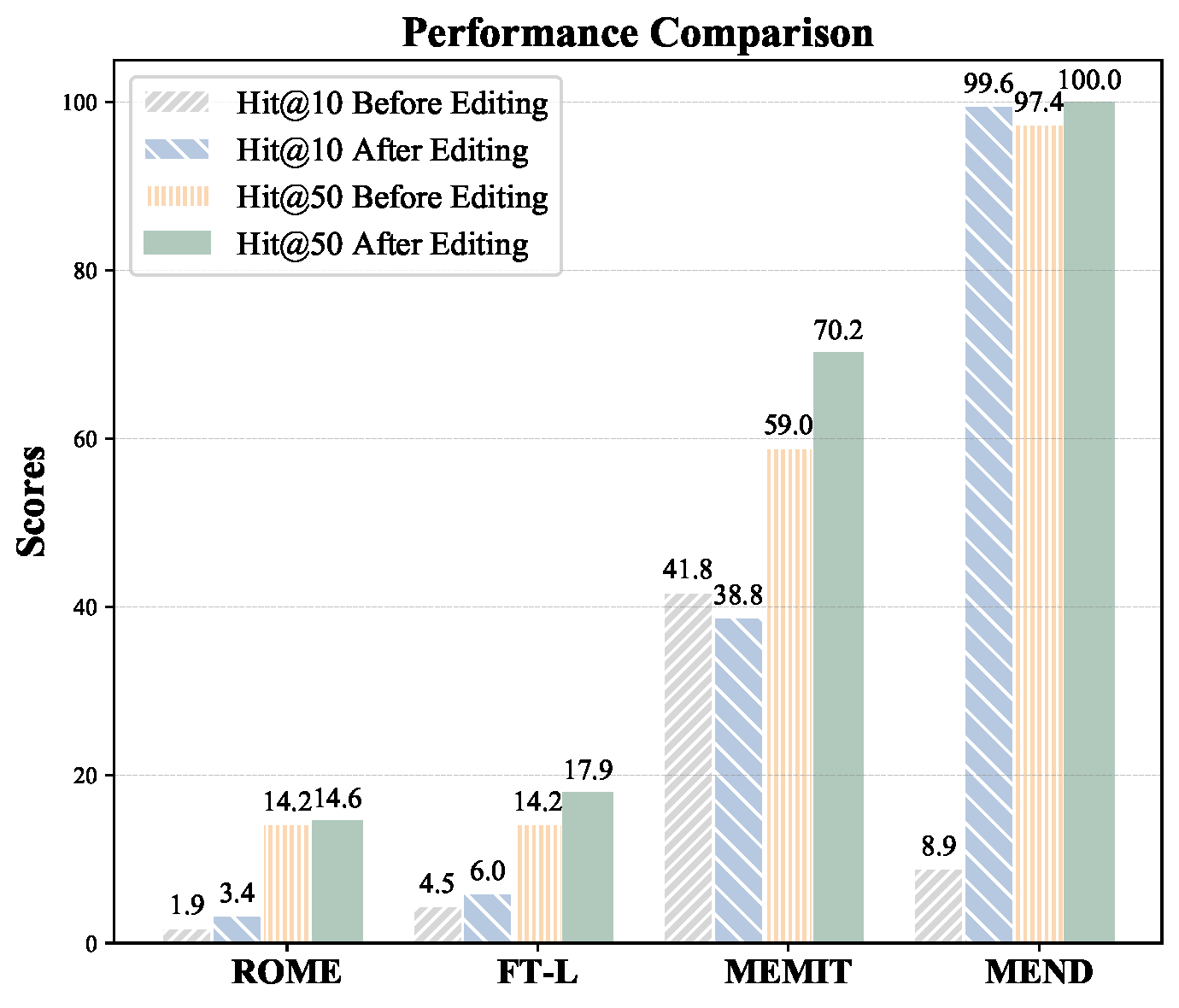
The Hit@10 and Hit@50 performance for the target knowledge in the model’s parameters before and after editing.
From the figure, we observe that MEND and MEMIT significantly inject the target knowledge into the parameters. Notably, MEND demonstrates a remarkable capacity for editing, with the Hit@50 rate already exceeding 90\% before the edit. This means that MEND might be able to find and change the right neurons that hold the target knowledge without having to do a full knowledge-locating analysis. After the editing process, we observe a substantial increase in the Hit@10 score. In fact, in our experiments, the Hit@1 for MEND is also above 90\% after editing, demonstrating its strong editing capacity. For MEMIT, we also observe an increase in Hit@50 (59.7\% $\rightarrow$ 70.2\%), and the original neurons already have a high Hit score before editing. However, for ROME and FT-L, we do not observe an increase in performance, indicating that their editing mechanisms require further investigation to understand their specific characteristics and limitations.
Sparsity
An important characteristic of knowledge editing is its intention to modify a specific piece of knowledge within the model.
This suggests an intuitive hypothesis that the
The heatmap shows how different model editing methods affect the weights of the model. Darker colors indicate more changes in the weights. The heatmap reveals which parts of the model are most sensitive to changes for each method.
ROME, MEND, and MEMIT exhibit a distinct pattern of sparse updates, while fine-tuning spreads its modifications more uniformly across weights. Particularly, for knowledge editing methods like ROME and MEMIT, it is intriguing to observe a concentrated focus on one or several columns of the value layer. This finding aligns with earlier research that emphasizes the value layer's pivotal role in encapsulating correlated knowledge. Regarding the MEND methods, we propose that the learned hypernetwork can be viewed as a tool or a "probe" that helps us explore and understand the internal mechanisms used by the model to encode knowledge, providing insights into how the model represents and processes information.
Mapping to Embedding Space
To further investigate the differences between different editing methods, we conduct an embedding space analysis following the approach of Dar et al.
They analyze the Transformer's parameters by mapping the weights of the LLMs to the vocabulary space and find that the embedding space can interpret these weights.
Here, we map the two matrices,
The Hit@10 and Hit@50 performance for the target knowledge in the model’s parameters before and after editing.
From the figure, we observe that MEND and MEMIT significantly inject the target knowledge into the parameters.
Notably, MEND demonstrates a remarkable capacity for editing, with the Hit@50 rate already exceeding 90\% before the edit.
This means that MEND might be able to find and change the right neurons that hold the target knowledge without having to do a full knowledge-locating analysis.
After the editing process, we observe a substantial increase in the Hit@10 score.
In fact, in our experiments, the Hit@1 for MEND is also above 90\% after editing, demonstrating its strong editing capacity.
For MEMIT, we also observe an increase in Hit@50 (59.7\%
Sparsity
An important characteristic of knowledge editing is its intention to modify a specific piece of knowledge within the model. This suggests an intuitive hypothesis that the $\Delta \boldsymbol{W}$ matrix is likely to be sparse. Following the approach of De Cao et al. , we present visualizations that capture weight updates resulting from knowledge edits, as depicted in Figure below.
The heatmap shows how different model editing methods affect the weights of the model. Darker colors indicate more changes in the weights. The heatmap reveals which parts of the model are most sensitive to changes for each method.
ROME, MEND, and MEMIT exhibit a distinct pattern of sparse updates, while fine-tuning spreads its modifications more uniformly across weights. Particularly, for knowledge editing methods like ROME and MEMIT, it is intriguing to observe a concentrated focus on one or several columns of the value layer. This finding aligns with earlier research that emphasizes the value layer's pivotal role in encapsulating correlated knowledge. Regarding the MEND methods, we propose that the learned hypernetwork can be viewed as a tool or a "probe" that helps us explore and understand the internal mechanisms used by the model to encode knowledge, providing insights into how the model represents and processes information.
Mapping to Embedding Space
To further investigate the differences between different editing methods, we conduct an embedding space analysis following the approach of Dar et al. They analyze the Transformer's parameters by mapping the weights of the LLMs to the vocabulary space and find that the embedding space can interpret these weights. Here, we map the two matrices, $\boldsymbol{W}'$ and $\boldsymbol{W}$, to observe the differences between these methods. From the sparsity analysis, we select the top five columns of the updated value matrix $\Delta \boldsymbol{W}$ and map the corresponding columns of $\boldsymbol{W}'$ and $\boldsymbol{W}$ into the embedding matrices $\boldsymbol{E}$ to obtain the logits in the vocabulary space. We then compute the Hit@10 and Hit@50 of the new knowledge in the output logits. We select cases from ZsRE where all four methods successfully edit the knowledge and present the average performance in Figure below.
The Hit@10 and Hit@50 performance for the target knowledge in the model’s parameters before and after editing.
From the figure, we observe that MEND and MEMIT significantly inject the target knowledge into the parameters. Notably, MEND demonstrates a remarkable capacity for editing, with the Hit@50 rate already exceeding 90\% before the edit. This means that MEND might be able to find and change the right neurons that hold the target knowledge without having to do a full knowledge-locating analysis. After the editing process, we observe a substantial increase in the Hit@10 score. In fact, in our experiments, the Hit@1 for MEND is also above 90\% after editing, demonstrating its strong editing capacity. For MEMIT, we also observe an increase in Hit@50 (59.7\% $\rightarrow$ 70.2\%), and the original neurons already have a high Hit score before editing. However, for ROME and FT-L, we do not observe an increase in performance, indicating that their editing mechanisms require further investigation to understand their specific characteristics and limitations.
Sparsity
An important characteristic of knowledge editing is its intention to modify a specific piece of knowledge within the model. This suggests an intuitive hypothesis that the $\Delta \boldsymbol{W}$ matrix is likely to be sparse. Following the approach of De Cao et al. , we present visualizations that capture weight updates resulting from knowledge edits, as depicted in Figure below.
The heatmap shows how different model editing methods affect the weights of the model. Darker colors indicate more changes in the weights. The heatmap reveals which parts of the model are most sensitive to changes for each method.
ROME, MEND, and MEMIT exhibit a distinct pattern of sparse updates, while fine-tuning spreads its modifications more uniformly across weights. Particularly, for knowledge editing methods like ROME and MEMIT, it is intriguing to observe a concentrated focus on one or several columns of the value layer. This finding aligns with earlier research that emphasizes the value layer's pivotal role in encapsulating correlated knowledge. Regarding the MEND methods, we propose that the learned hypernetwork can be viewed as a tool or a "probe" that helps us explore and understand the internal mechanisms used by the model to encode knowledge, providing insights into how the model represents and processes information.
The Effectiveness of Knowledge Locating in LLMs
We adopt the computing of the \textbf{Relative Similarity} (RSim) as:
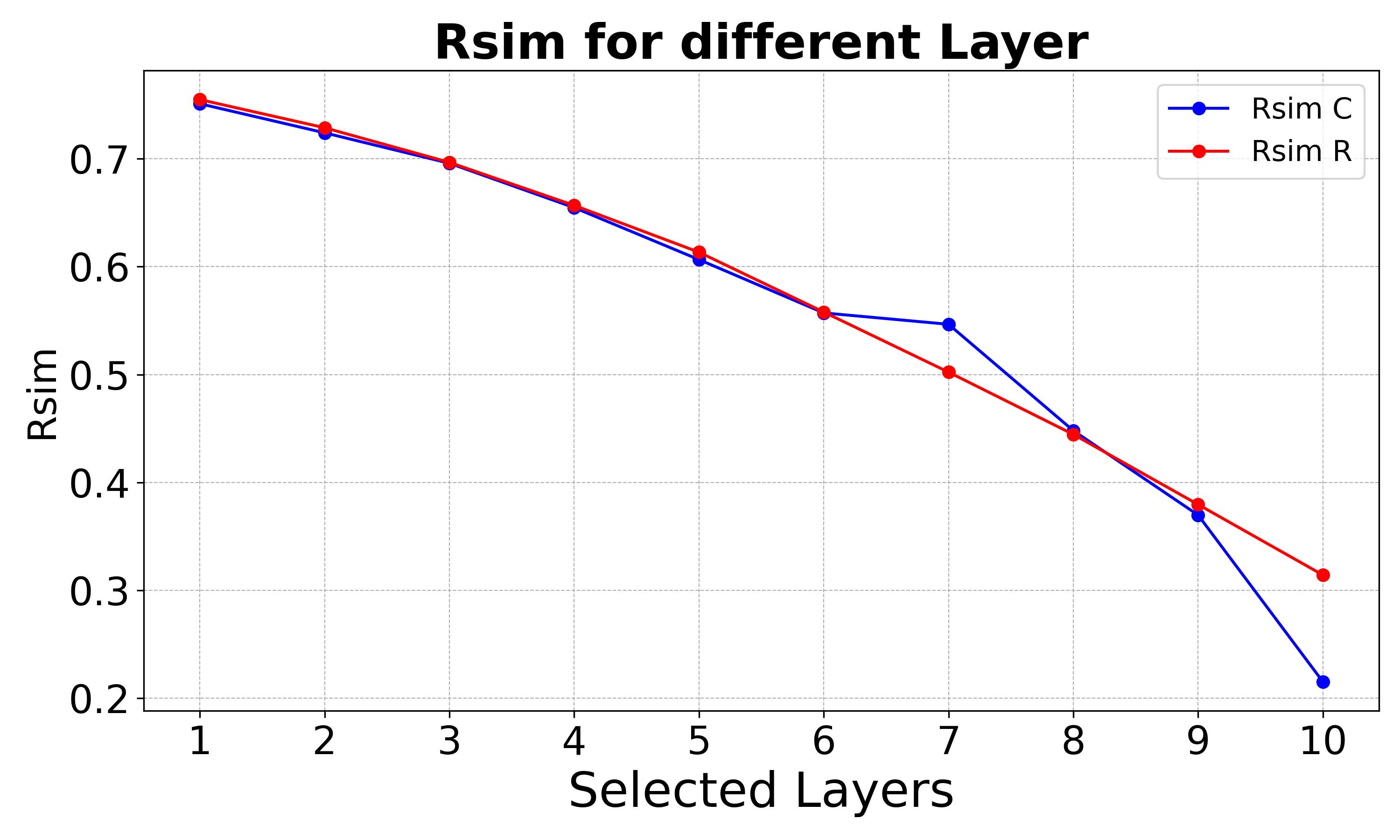
RSim for the different number of layers.
Here, we can find the Rsim score is less than 0.6 when we consider more than five layers for both consistency and relevance, which means the locating results for unrelated knowledge and related knowledge chains didn't show much difference. To be more tangible, we conduct a case study here.
Case Study
We consider three settings for a given fact associated with the entity SMAP and show it in Figure below.
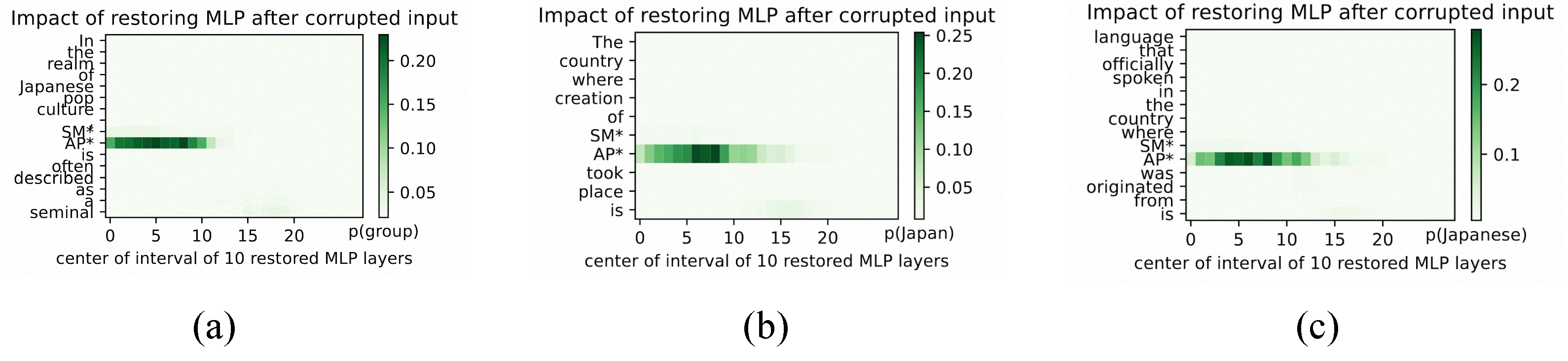
First, we conduct a causal analysis of the fact with the entity [
We first conduct a causal analysis of the fact: [
The Implicit Knowledge Structure in LLMs
Understanding the knowledge structure in LLM is crucial for effective knowledge editing. Previous research often conceptualized knowledge within LLMs as resembling triples in Knowledge Graphs (KG), comprising subjects, relations, and objects. This analogy, while useful, simplifies the intricate nature of knowledge representation in LLMs.
Editing knowledge in a KG, where the task usually involves modifying a single relationship between two nodes, is comparatively straightforward. KGs inherently support easy reasoning tasks and allow for the preservation of the rest of the knowledge structure. This resilience is illustrated in Figure below, where edits and subsequent recovery processes result in the complete restoration of the original KG structure.
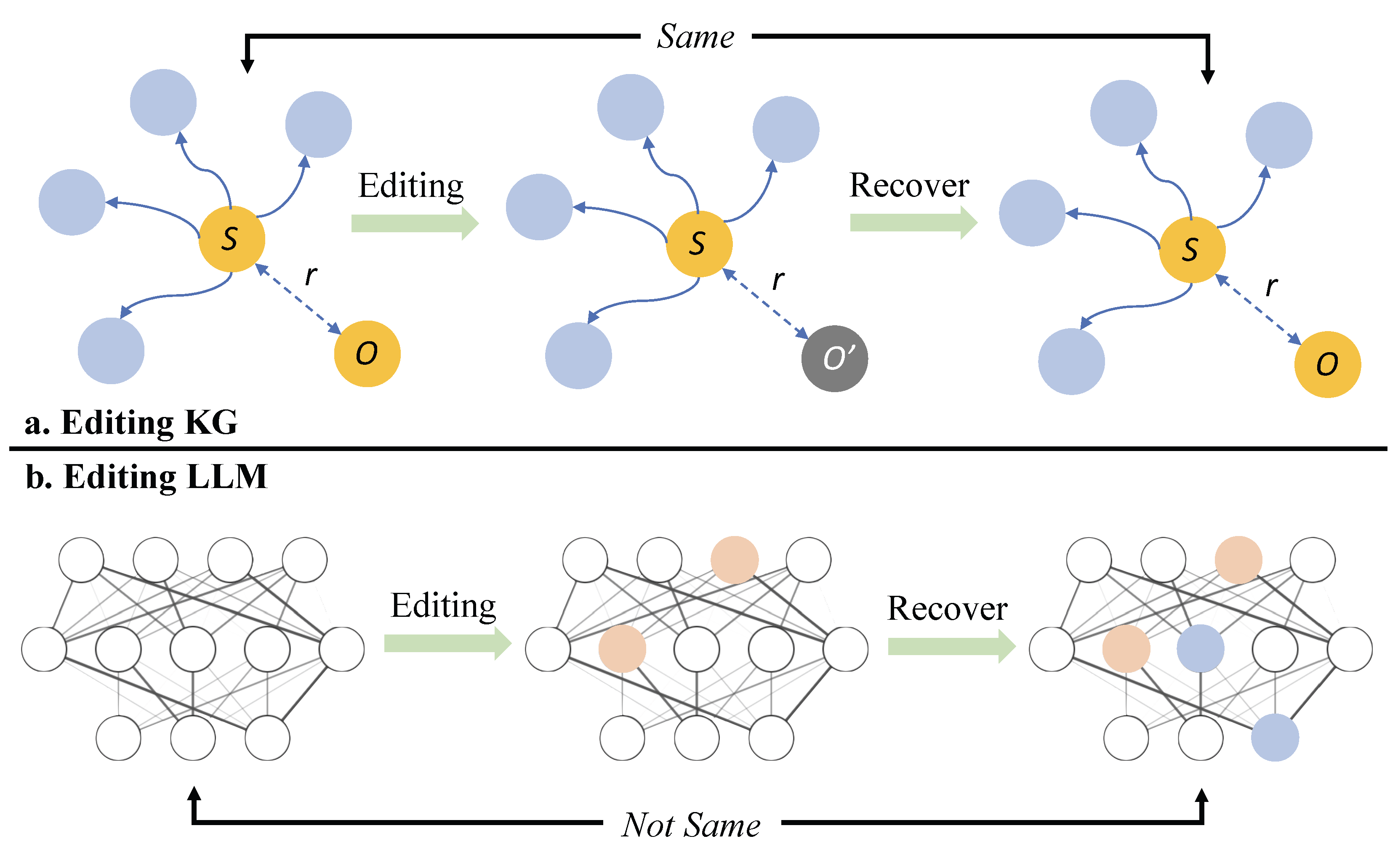
Comparison of editing effects on Knowledge Graphs vs. LLMs: Demonstrating the abil- ity of Knowledge Graphs to fully restore their original structure after edits and recovery processes, in contrast to LLMs where similar recovery efforts fail to reinstate the original model
On the other hand, knowledge editing in LLMs presents unique challenges due to the entangled nature of knowledge within these models. Unlike KGs, where knowledge is neatly compartmentalized, in LLMs, knowledge is distributed across various parameters and layers, making it difficult to isolate and edit specific information without affecting other knowledge areas. The current perspective of viewing knowledge in LLMs as triples is somewhat limited and fails to capture the full complexity and interconnected nature of these models. This complexity is further highlighted by previous work, who discuss the challenges of modifying intrinsic knowledge within parameters.
Furthermore, previous research has revealed that knowledge editing in LLMs can lead to unintended propagation effects. Li et al. illustrates that current knowledge editing methods can result in knowledge conflict and knowledge distortion within LLMs. Unlike structured knowledge bases, neural networks lack strict constraints on knowledge structure and interrelationships. This makes it difficult to confine edits to a localized scope within the model, and the free-form nature of LLMs further complicates the editing process. Consequently, a more comprehensive understanding of the LM's mechanisms is required.
Currently, methods like T-Patcher or IKE offer plug-and-play functionality and easy reversibility. They provide flexibility and user-friendliness and can be easily integrated into or detached from the LLMs as needed. These methods aim to mitigate some of the challenges associated with knowledge editing in LLMs, allowing for convenient and reversible modifications. As the field evolves, it is imperative to continue developing methods that not only address the challenges of knowledge editing but also harness the full potential of these complex systems, turning vanilla LLMs into WikiModels, a.k.a., neural knowledge bases that is feasibility for editing.
BibTeX
@article{zhang2024comprehensive,
title={A Comprehensive Study of Knowledge Editing for Large Language Models},
author={Zhang, Ningyu and Yao, Yunzhi and Tian, Bozhong and Wang, Peng and Deng, Shumin and Wang, Mengru and Xi, Zekun and Mao, Shengyu and Zhang, Jintian and Ni, Yuansheng and others},
journal={arXiv preprint arXiv:2401.01286},
year={2024}
}
@article{wang2023easyedit,
title={EasyEdit: An Easy-to-use Knowledge Editing Framework for Large Language Models},
author={Wang, Peng and Zhang, Ningyu and Xie, Xin and Yao, Yunzhi and Tian, Bozhong and Wang, Mengru and Xi, Zekun and Cheng, Siyuan and Liu, Kangwei and Zheng, Guozhou and others},
journal={arXiv preprint arXiv:2308.07269},
year={2023}
}
@article{yao2023editing,
title={Editing Large Language Models: Problems, Methods, and Opportunities},
author={Yao, Yunzhi and Wang, Peng and Tian, Bozhong and Cheng, Siyuan and Li, Zhoubo and Deng, Shumin and Chen, Huajun and Zhang, Ningyu},
journal={arXiv preprint arXiv:2305.13172},
year={2023}
}