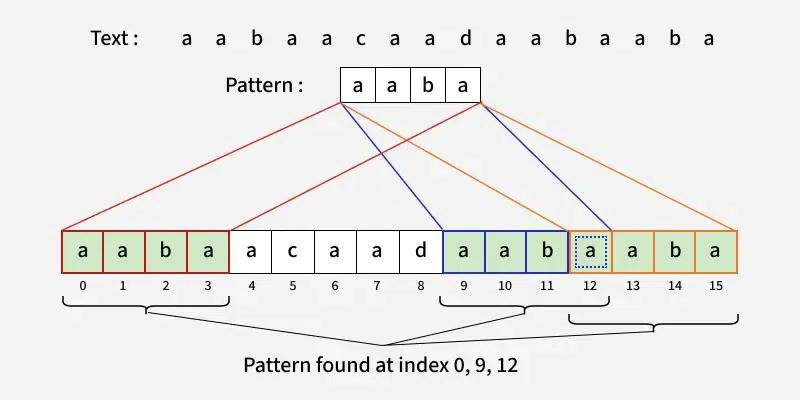
Given two strings: txt, representing the main text, and pat, representing the pattern to be searched. Find and return all starting indices in txt where the string pat appears as a substring. The matching should be exact, and the indices should be 0-based, meaning the first character of txt is considered to be at index 0.
Examples:
Input: txt = "abcab", pat = "ab" Output: [0, 3] Explanation: The string "ab" occurs twice in txt, first occurrence starts from index 0 and second from index 3.
[Naive Approach] Naive Pattern Searching Algorithm - O(n × m) Time and O(1) Space
We start at every index in the text and compare it with the first character of the pattern. If they match, we move to the next character in both text and pattern. If there is a mismatch, we start the same process for the next index of the text.
C++
#include<iostream>#include<vector>#include<string>usingnamespacestd;vector<int>search(string&pat,string&txt){vector<int>res;intn=txt.size();intm=pat.size();for(inti=0;i<=n-m;i++){intj=0;// compare pattern with substring // starting at index iwhile(j<m&&txt[i+j]==pat[j]){j++;}// if full pattern matchedif(j==m){res.push_back(i);}}returnres;}intmain(){stringtxt="aabaacaadaabaaba";stringpat="aaba";vector<int>res=search(pat,txt);for(inti=0;i<res.size();i++)cout<<res[i]<<" ";return0;}
Java
importjava.util.ArrayList;classGfG{staticArrayList<Integer>search(Stringpat,Stringtxt){ArrayList<Integer>res=newArrayList<>();intn=txt.length();intm=pat.length();for(inti=0;i<=n-m;i++){intj=0;// compare pattern with substring // starting at index iwhile(j<m&&txt.charAt(i+j)==pat.charAt(j)){j++;}// if full pattern matchedif(j==m){res.add(i);}}returnres;}publicstaticvoidmain(String[]args){Stringtxt="aabaacaadaabaaba";Stringpat="aaba";ArrayList<Integer>res=search(pat,txt);for(inti=0;i<res.size();i++)System.out.print(res.get(i)+" ");}}
Python
defsearch(pat,txt):res=[]n=len(txt)m=len(pat)foriinrange(n-m+1):j=0# compare pattern with substring # starting at index iwhilej<mandtxt[i+j]==pat[j]:j+=1# if full pattern matchedifj==m:res.append(i)returnresif__name__=="__main__":txt="aabaacaadaabaaba"pat="aaba"res=search(pat,txt)foridxinres:print(idx,end=" ")
C#
usingSystem;usingSystem.Collections.Generic;classGfG{staticList<int>search(stringpat,stringtxt){List<int>res=newList<int>();intn=txt.Length;intm=pat.Length;for(inti=0;i<=n-m;i++){intj=0;// compare pattern with substring // starting at index iwhile(j<m&&txt[i+j]==pat[j]){j++;}// if full pattern matchedif(j==m){res.Add(i);}}returnres;}staticvoidMain(){stringtxt="aabaacaadaabaaba";stringpat="aaba";List<int>res=search(pat,txt);for(inti=0;i<res.Count;i++)Console.Write(res[i]+" ");}}
JavaScript
// compare pattern with substring // starting at index ifunctionsearch(pat,txt){letres=[];letn=txt.length;letm=pat.length;for(leti=0;i<=n-m;i++){letj=0;// compare pattern with substring // starting at index iwhile(j<m&&txt[i+j]===pat[j]){j++;}// if full pattern matchedif(j===m){res.push(i);}}returnres;}// Driver Codelettxt="aabaacaadaabaaba";letpat="aaba";letres=search(pat,txt);for(leti=0;i<res.length;i++)process.stdout.write(res[i]+" ");
The KMP algorithm improves pattern matching by avoiding rechecking characters after a mismatch. It uses the degenerating property of patterns — repeated sub-patterns — to skip unnecessary comparisons.
Whenever a mismatch happens after some matches, we already know part of the pattern has matched earlier. KMP uses this information through a preprocessed LPS (Longest Prefix Suffix) array to shift the pattern efficiently, without restarting from the next character in the text.
This allows KMP to run in O(n + m) time, where n is the length of the text and m is the length of the pattern.
Terminologies used in KMP Algorithm:
text (txt): The main string in which we want to search for a pattern.
pattern (pat): The substring we are trying to find within the text.
Match: A match occurs when all characters of the pattern align exactly with a substring of the text.
LPS Array (Longest Prefix Suffix): For each position i in the pattern, lps[i] stores the length of the longest proper prefix which is also a suffix in the substring pat[0...i].
Proper Prefix: A proper prefix is a prefix that is not equal to the whole string.
Suffix: A suffix is a substring that ends at the current position.
The LPS array helps us determine how much we can skip in the pattern when a mismatch occurs, thus avoiding redundant comparisons.
Example of lps[] construction:
Example 1: Pattern "aabaaac"
At index 0: "a" → No proper prefix/suffix → lps[0] = 0 At index 1: "aa" → "a" is both prefix and suffix → lps[1] = 1 At index 2: "aab" → No prefix matches suffix → lps[2] = 0 At index 3: "aaba" → "a" is prefix and suffix → lps[3] = 1 At index 4: "aabaa" → "aa" is prefix and suffix → lps[4] = 2 At index 5: "aabaaa" → "aaa" is prefix and suffix → lps[5] = 3 At index 6: "aabaaac" → Mismatch, so reset → lps[6] = 0 Final lps[]: [0, 1, 0, 1, 2, 3, 0]
Example 2: Pattern "abcdabca"
At index 0: lps[0] = 0 At index 1: lps[1] = 0 At index 2:lps[2] = 0 At index 3: lps[3] = 0 (no repetition in "abcd") At index 4:lps[4] = 1 ("a" repeats) At index 5: lps[5] = 2 ("ab" repeats) At index 6: lps[6] = 3 ("abc" repeats) At index 7: lps[7] = 1 (mismatch, fall back to "a") Final LPS: [0, 0, 0, 0, 1, 2, 3, 1]
Note: lps[i] could also be defined as the longest prefix which is also a proper suffix. We need to use it properly in one place to make sure that the whole substring is not considered.
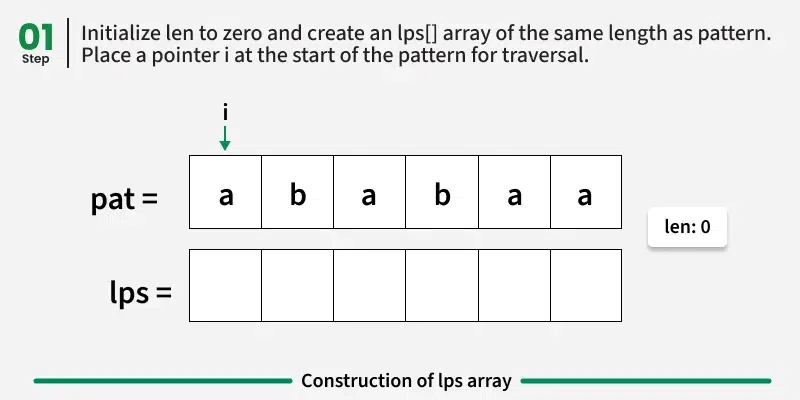
Algorithm for Construction of LPS Array:
The value of lps[0] is always 0 because a string of length one has no non-empty proper prefix that is also a suffix. We maintain a variable len, initialized to 0, which keeps track of the length of the previous longest prefix suffix. As we traverse the pattern from index 1 onward, we compare the current character pat[i] with pat[len]. Based on this comparison, we have three possible cases:
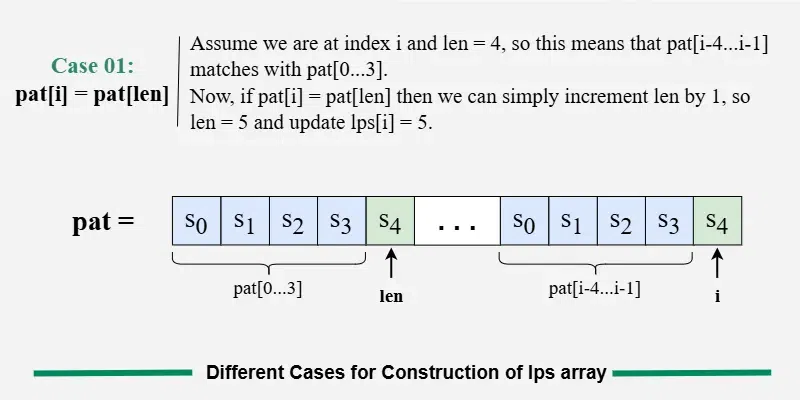
Case 1: pat[i] == pat[len]
This means the current character continues the existing prefix-suffix match. → We increment len by 1 and assign lps[i] = len. → Then, move to the next index.
Case 2: pat[i] != pat[len] and len == 0
There is no prefix that matches any suffix ending at i, and we can't fall back to any earlier matching pattern. → So we set lps[i] = 0 and simply move to the next character.
Case 3: pat[i] != pat[len] and len > 0
We cannot extend the previous matching prefix-suffix. However, there might still be a shorter prefix which is also a suffix that matches the current position. Instead of comparing all prefixes manually, we reuse previously computed LPS values. → Since pat[0...len-1] equals pat[i-len...i-1], we can fall back to lps[len - 1] and update len. → This reduces the prefix size we're matching against and avoids redundant work. We do not increment i immediately in this case — instead, we retry the current pat[i] with the new updated len.
Illustration:
1 / 5
Example of Construction of LPS Array:
1 / 9
Implementation of KMP Algorithm:
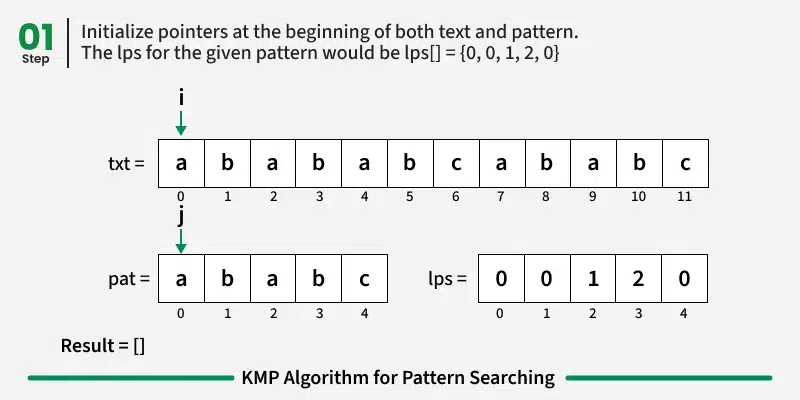
We initialize two pointers — one for the text string and another for the pattern. When the characters at both pointers match, we increment both pointers and continue the comparison. If they do not match, we reset the pattern pointer to the last value from the LPS array, since that portion of the pattern has already been matched with the text. Additionally, if we have traversed the entire pattern string (i.e., a full match is found), we add the starting index of the pattern's occurrence in the text to the result, and continue the search from the LPS value of the last element in the pattern.
Let’s say we are at position i in the text string and position j in the pattern string when a mismatch occurs:
At this point, we know that pat[0..j-1] has already matched with txt[i-j..i-1].
The value of lps[j-1] represents the length of the longest proper prefix of the substring pat[0..j-1] that is also a suffix of the same substring.
From these two observations, we can conclude that there's no need to recheck the characters in pat[0..lps[j-1]]. Instead, we can directly resume our search from lps[j-1].
1 / 14
C++
#include<iostream>#include<string>#include<vector>usingnamespacestd;voidconstructLps(string&pat,vector<int>&lps){// len stores the length of longest prefix which// is also a suffix for the previous indexintlen=0;// lps[0] is always 0lps[0]=0;inti=1;while(i<pat.length()){// If characters match, increment the size of lpsif(pat[i]==pat[len]){len++;lps[i]=len;i++;}// If there is a mismatchelse{if(len!=0){// Update len to the previous lps value// to avoid reduntant comparisonslen=lps[len-1];}else{// If no matching prefix found, set lps[i] to 0lps[i]=0;i++;}}}}vector<int>search(string&pat,string&txt){intn=txt.length();intm=pat.length();vector<int>lps(m);vector<int>res;constructLps(pat,lps);// Pointers i and j, for traversing// the text and patterninti=0;intj=0;while(i<n){// If characters match, move both pointers forwardif(txt[i]==pat[j]){i++;j++;// If the entire pattern is matched// store the start index in resultif(j==m){res.push_back(i-j);// Use LPS of previous index to// skip unnecessary comparisonsj=lps[j-1];}}// If there is a mismatchelse{// Use lps value of previous index// to avoid redundant comparisonsif(j!=0)j=lps[j-1];elsei++;}}returnres;}intmain(){stringtxt="aabaacaadaabaaba";stringpat="aaba";vector<int>res=search(pat,txt);for(inti=0;i<res.size();i++)cout<<res[i]<<" ";return0;}
Java
importjava.util.ArrayList;classGfG{staticvoidconstructLps(Stringpat,int[]lps){// len stores the length of longest prefix which // is also a suffix for the previous indexintlen=0;// lps[0] is always 0lps[0]=0;inti=1;while(i<pat.length()){// If characters match, increment the size of lpsif(pat.charAt(i)==pat.charAt(len)){len++;lps[i]=len;i++;}// If there is a mismatchelse{if(len!=0){// Update len to the previous lps value // to avoid redundant comparisonslen=lps[len-1];}else{// If no matching prefix found, set lps[i] to 0lps[i]=0;i++;}}}}staticArrayList<Integer>search(Stringpat,Stringtxt){intn=txt.length();intm=pat.length();int[]lps=newint[m];ArrayList<Integer>res=newArrayList<>();constructLps(pat,lps);// Pointers i and j, for traversing // the text and patterninti=0;intj=0;while(i<n){// If characters match, move both pointers forwardif(txt.charAt(i)==pat.charAt(j)){i++;j++;// If the entire pattern is matched // store the start index in resultif(j==m){res.add(i-j);// Use LPS of previous index to // skip unnecessary comparisonsj=lps[j-1];}}// If there is a mismatchelse{// Use lps value of previous index// to avoid redundant comparisonsif(j!=0)j=lps[j-1];elsei++;}}returnres;}publicstaticvoidmain(String[]args){Stringtxt="aabaacaadaabaaba";Stringpat="aaba";ArrayList<Integer>res=search(pat,txt);for(inti=0;i<res.size();i++)System.out.print(res.get(i)+" ");}}
Python
defconstructLps(pat,lps):# len stores the length of longest prefix which # is also a suffix for the previous indexlen_=0m=len(pat)# lps[0] is always 0lps[0]=0i=1whilei<m:# If characters match, increment the size of lpsifpat[i]==pat[len_]:len_+=1lps[i]=len_i+=1# If there is a mismatchelse:iflen_!=0:# Update len to the previous lps value # to avoid redundant comparisonslen_=lps[len_-1]else:# If no matching prefix found, set lps[i] to 0lps[i]=0i+=1defsearch(pat,txt):n=len(txt)m=len(pat)lps=[0]*mres=[]constructLps(pat,lps)# Pointers i and j, for traversing # the text and patterni=0j=0whilei<n:# If characters match, move both pointers forwardiftxt[i]==pat[j]:i+=1j+=1# If the entire pattern is matched # store the start index in resultifj==m:res.append(i-j)# Use LPS of previous index to # skip unnecessary comparisonsj=lps[j-1]# If there is a mismatchelse:# Use lps value of previous index# to avoid redundant comparisonsifj!=0:j=lps[j-1]else:i+=1returnresif__name__=="__main__":txt="aabaacaadaabaaba"pat="aaba"res=search(pat,txt)foriinrange(len(res)):print(res[i],end=" ")
C#
usingSystem;usingSystem.Collections.Generic;classGfG{staticvoidconstructLps(stringpat,int[]lps){// len stores the length of longest prefix which // is also a suffix for the previous indexintlen=0;// lps[0] is always 0lps[0]=0;inti=1;while(i<pat.Length){// If characters match, increment the size of lpsif(pat[i]==pat[len]){len++;lps[i]=len;i++;}// If there is a mismatchelse{if(len!=0){// Update len to the previous lps value // to avoid redundant comparisonslen=lps[len-1];}else{// If no matching prefix found, set lps[i] to 0lps[i]=0;i++;}}}}staticList<int>search(stringpat,stringtxt){intn=txt.Length;intm=pat.Length;int[]lps=newint[m];List<int>res=newList<int>();constructLps(pat,lps);// Pointers i and j, for traversing // the text and patterninti=0;intj=0;while(i<n){// If characters match, move both pointers forwardif(txt[i]==pat[j]){i++;j++;// If the entire pattern is matched // store the start index in resultif(j==m){res.Add(i-j);// Use LPS of previous index to // skip unnecessary comparisonsj=lps[j-1];}}// If there is a mismatchelse{// Use lps value of previous index// to avoid redundant comparisonsif(j!=0)j=lps[j-1];elsei++;}}returnres;}staticvoidMain(string[]args){stringtxt="aabaacaadaabaaba";stringpat="aaba";List<int>res=search(pat,txt);for(inti=0;i<res.Count;i++)Console.Write(res[i]+" ");}}
JavaScript
functionconstructLps(pat,lps){// len stores the length of longest prefix which // is also a suffix for the previous indexletlen=0;// lps[0] is always 0lps[0]=0;leti=1;while(i<pat.length){// If characters match, increment the size of lpsif(pat[i]===pat[len]){len++;lps[i]=len;i++;}// If there is a mismatchelse{if(len!==0){// Update len to the previous lps value // to avoid redundant comparisonslen=lps[len-1];}else{// If no matching prefix found, set lps[i] to 0lps[i]=0;i++;}}}}functionsearch(pat,txt){constn=txt.length;constm=pat.length;constlps=newArray(m);constres=[];constructLps(pat,lps);// Pointers i and j, for traversing // the text and patternleti=0;letj=0;while(i<n){// If characters match, move both pointers forwardif(txt[i]===pat[j]){i++;j++;// If the entire pattern is matched // store the start index in resultif(j===m){res.push(i-j);// Use LPS of previous index to // skip unnecessary comparisonsj=lps[j-1];}}// If there is a mismatchelse{// Use lps value of previous index// to avoid redundant comparisonsif(j!==0)j=lps[j-1];elsei++;}}returnres;}// Driver Codeconsttxt="aabaacaadaabaaba";constpat="aaba";constres=search(pat,txt);console.log(res.join(" "));
Output
0 9 12
Time Complexity: O(n + m), where n is the length of the text and m is the length of the pattern. This is because creating the LPS (Longest Prefix Suffix) array takes O(m) time, and the search through the text takes O(n) time.
Auxiliary Space: O(m), as we need to store the LPS array of size m.
We use cookies to ensure you have the best browsing experience on our website. By using our site, you
acknowledge that you have read and understood our
Cookie Policy &
Privacy Policy
Improvement
Suggest Changes
Help us improve. Share your suggestions to enhance the article. Contribute your expertise and make a difference in the GeeksforGeeks portal.
Create Improvement
Enhance the article with your expertise. Contribute to the GeeksforGeeks community and help create better learning resources for all.