Google Cloudが、2023年3月30日午前1時(日本時間)からグローバルカンファレンス「Google Data Cloud & AI Summit」をオンライン開催した。同日午後、グーグル・クラウド・ジャパンがその内容をもとに、データソリューション関連の新発表に関する記者説明会を開催した。

グーグル・クラウド・ジャパン ソリューション&テクノロジー部門 技術部長(DB, Analytics & ML)の寳野雄太氏
BigQueryの新価格体系「BigQuery Editions」が登場、コスト効率を高める
Google Data Cloud & AI Summitは、データの利活用をテーマに、データベース、データアナリティクス、ビジネスインテリジェンス、AI技術に関するGoogle Cloudの最新ソリューションや専門的知見を紹介するグローバルカンファレンス。基調講演のほか、14のブレイクアウトセッションやデモストレーションが行われた。
グーグル・クラウド・ジャパン ソリューション&テクノロジー部門 技術部長(DB, Analytics & ML)の寳野雄太氏は、今回のイベントでは「データアナリティクスの領域で『柔軟性』『プライバシーセーフなデータ共有』『ビジネス価値の加速』という3点から、新たな発表が行われた」と総括した。
まず「柔軟性」においては、BigQueryの新しい価格体系となる「BigQuery Editions」を発表している。寶野氏は「より低コストでデータクラウドのコンセプトを実現してもらうための価格体系。さまざまなワークロードに応じた機能やSLA、コストに最適な価格で提供することができる」と説明した。
BigQuery Editionsでは、Standard Edition、Enterprise Edition、Enterprise Plusという3種類の価格体系が用意されており、ワークロードごとに最適な価格とパフォーマンスを提供できるという。1年間または3年間の利用確約により大幅な割引が得られるほか、同一の組織内で異なるEditionを混在させることも可能だ。

「BigQuery Editions」の概要
「Autoscaling(オートスケーリング)」と「Compressed Storage(圧縮ストレージ)」という2つの新機能により、コストを制御しながら利用することも可能になっている。
Autoscalingは、コストの予測性を高め、予算を超えない範囲で柔軟にBigQueryを活用したいという要望に対応した機能。クエリ要求に応じてコンピュートキャパシティをダイナミックに調整し、利用しなかったキャパシティについては支払いがないため、コストパフォーマンスを最大40%向上させる。その一方で、支払うコストの上限設定に応じて最大スロットが用意されるため、コストの予測も立てやすい。
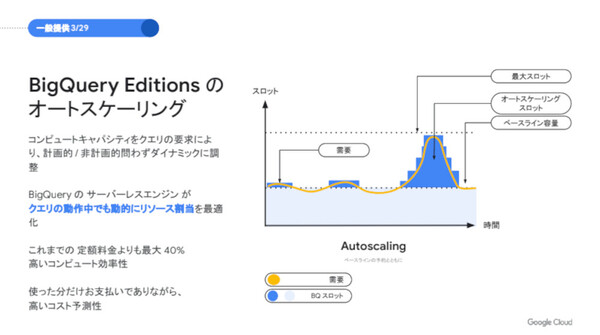
BigQuery Editionsの「Autoscaling」概要
Compressed Storageは、ストレージサービスにおいて、論理サイズによる課金ではなく、BigQueryの圧縮テクノロジーを活用した圧縮後の物理サイズによる課金へ移行するもの。現在はあらゆるタイプのデータ(構造化、非構造化、半構造化)が増加しているが、より低コストでそうした環境をサポートする。
「これは、10年以上に渡って進化してきたBigQueryの圧縮テクノロジーで実現するもの。Compressed Storageを適用したExabeamでは12分の1の圧縮レートを実現し、コスト低減に大きなインパクトをもたらす。99%の顧客が(Compressed Storageによる)圧縮サイズの課金を選んだほうが得になる」(寶野氏)

BigQuery Editionsの「Compressed Storage」概要
プライバシーを保護しながら柔軟にデータ共有できる「Data Clean Room」
2つめの「プライバシーセーフなデータ共有」では、新機能「BigQuery Data Clean Room」について紹介した。これは、プライバシーを保護しながら他社とのデータ共有などができる環境を提供するもの。生データの共有/持ち出し防止だけでなく、クエリ結果や集約した結果のみを提供するといった処理が可能だ。
「Data Clean Roomを使うことで、たとえばプライバシー保護を行いながらマーケティングキャンペーンデータをファーストパーティデータと統合し、洞察を得るといったことができるようになった」(寶野氏)

「BigQuery Data Clean Room」の概要
3つめの「ビジネス価値の加速」では、「Looker Modeler」が発表された。
「いままでのLookerはBIツールととらえられていたが、Google Cloudでは『データを活用するアプリケーションのためのフレームワーク』と位置づけている。Lokker Modelerによって、LookerのセマンティックモデルをLooker StudioやConnectde Sheetsだけでなく、TableauやPower BIといった他社製品で利用し、異なるデータソースをブレンドした分析から洞察を生み出すことができる。セキュリティやデータガバナンスを利かすこともできる」(寶野氏)
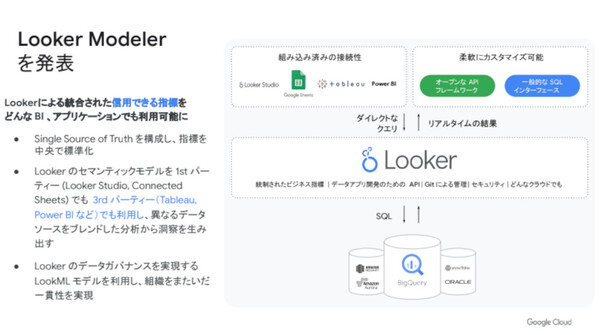
「Looker Modeler」の概要
さらに、BigQuery上でML(機械学習)による予測を可能にする「BigQuery Inference Engine」も発表されている。寶野氏は、SQLだけで機械学習モデルを作成できる「BigQuery ML」が高い人気を博しているとしたうえで、BigQuery Inference EngineはこのBigQuery MLなどでトレーニングしたモデルを使い、BigQuery上で推論処理ができると説明した。

「BigQuery Inference Engine」の概要
なおトランザクショナルデータベース関連では、PostgreSQL互換の高速データベース「Alloy DB」がGA(一般提供開始)になったこともあらためて紹介された。
「AlloyDBは99.99%の可用性を持ち、PostgreSQLよりもトランザクショナルワークロードのスループットが4倍高速。さらに、100倍以上高速な分析クエリにより、リアルタイムなビジネス洞察を可能にする」(寶野氏)
このAlloyDBをコンテナ化して柔軟に配置できるようにした「AlloyDB Omni」もプレビュー版として発表された。
「AlloyDBの革新的なテクノロジーを様々な場所で利用したいというニーズに対応したもの。開発者は、まず自分のラップトップ上でAlloyDBを検証することができ、オンプレミスのアプリケーションの統合を検証したいといった場合にも簡単に活用できる」(寶野氏)

