アマゾン ウェブ サービス ジャパンは、2024年6月20日と21日、国内最大の年次イベントである「AWS Summit Japan」をハイブリッドで開催。150を超えるセッションが展開された。
本記事では、全日本空輸(ANA)によるセッション「ANAグループ4万人に展開するデータマネジメント基盤の裏側」をレポートする。登壇したのは、デジタル変革室 イノベーション推進部 データマネジメントチームの丸山雄大氏。
丸山氏が所属するデータマネジメントチームは、ANAを中心としたグループのデータ戦略の策定、データ基盤の整備、開発管理などを担っている。同セッションでは、同グループの“データの民主化”の実現に向けた取り組みが、チームで得られた“14の秘伝”を通じて披露された。

全日本空輸 デジタル変革室 イノベーション推進部 データマネジメントチーム 丸山雄大氏、成田国際空港のグランドスタッフからデータマネジメントチームに転身した
ANAグループで得られたデータで、4万人の社員が価値を創りだせる体制へ
ANAグループは、主力ブランドのANAに加え、Peach Aviationやエアージャパンといった航空事業を展開している。近年では“マイルで生活できる世界”の実現に向け、ANA PayやANA Mallといったノンエア領域のサービスにも注力する。

ANAグループのさまざまな業務を支えるのが4万人の社員
このようなグループの成長やテクノロジーの進化に伴い、発生するデータの量も増加している。丸山氏は、「このデータの活用に、グループ4万人の社員の力を活かしたい。三人寄れば文殊の知恵ではないが、4万人の知恵が集まれば、思いもよらない価値が創出できるのではないか」と説明する。
そこでデータマネジメントチームが進めるのが、ANAグループにおける“データの民主化”だ。グループの各社員が、自由にデータをあつかい、価値を生み出せる状態を目指す。
これまでのデータ活用は、データの収集・汎用化から加工・集計、分析、共有まで、すべてシステム部門が実行してきた。それを、データの収集・汎用化はシステム部門中心、そしてデータ活用の主役はビジネス部門として、両部門で協創しながら実行していく体制に変革した。

ANAグループのデータの民主化のイメージ
この変革の推進を通じて、“秘伝”ともいうべき気づきがいくつも得られたという。まずは、データ活用のための環境、仕組みにおける秘伝が披露された。
データ活用の仕組みにおける秘伝:Amazon S3を中核に、堅牢性と柔軟性を両立した「BuleLake」を構築
秘伝1:データを物理的に1か所に集める戦略
ANAでは、データを蓄積する基盤として「BlueLake」、蓄積されたデータを活用するツールとして「BlueLake Apps」と呼ぶ仕組みを構築している。かつてのデータ基盤はエアラインに特化しており、データの民主化に向け、より統合的なデータ基盤であるBlueLakeを再構築した。
データ管理には様々な手法があるが、BlueLakeでは、物理的にデータを集約して一元管理している。
データは、個別の業務に特化したシステムから集約するため、それぞれ型や持ち方、キーなどが異なる。加えて、SaaSを活用する機会も増え、データの複雑性が増している。より一貫性のあるデータ管理を実現するために、この選択肢をとった。
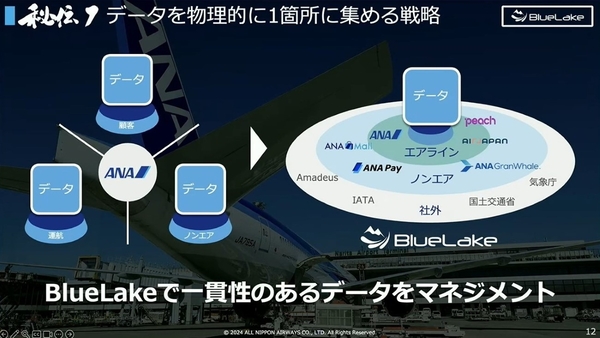
秘伝1:データを物理的に1か所に集める戦略
秘伝2:プライバシーに配慮した2層構造
物理的に集約されたデータは、多くの社員が自由にあつかえるよう、プライバシーに配慮した2層構造で管理されている。
具体的なアーキテクチャーは、Amazon S3を活用したデータレイク、Amazon RedShiftとSnowflakeを活用したDWH(データウェアハウス)で構成。生データをあつかうデジタルマーケティングやサービス活用向けの層と、仮名加工データをあつかうデータ集計やBI、機械学習に活用する層を、別のAWSアカウントで、完全に分離したかたちで運用している。
これにより、データの堅牢性担保と柔軟性を両立。グループの4万人が自由に使えるのは仮名加工データをあつかう層となり、個人情報保護法やGDPRなどに対応する。
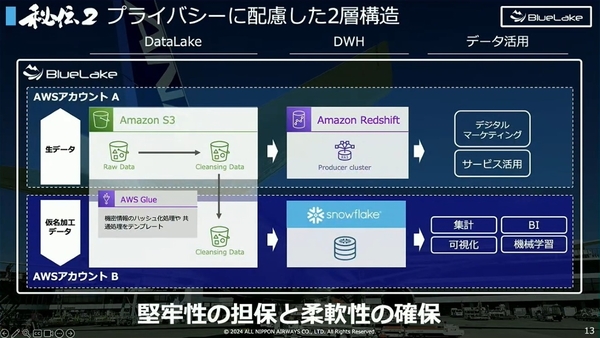
秘伝2:プライバシーに配慮した2層構造
秘伝3:Amazon S3を中心としたアーキテクチャー
前述のとおり、データレイクにはAmazon S3を活用するが、同ストレージサービスをマスターとして、時代や戦略に合わせてサービスを使い分ける戦略をとる。
「データ活用のトレンドの移り変わりは非常に速い。それに合わせて、毎回抜本的にアーキテクチャーを刷新するのはコストがかかる。Amazon S3はコネクタが豊富で、Delta LakeやApache Icebergといったフォーマットにも対応する」(丸山氏)

秘伝3:Amazon S3を中心としたアーキテクチャー
秘伝4:目的やレベル別に多種なツールを整備
データ活用のためのツールも、目的やレベル別に、6つのツールを整備している。機微情報を扱う「BuleLake Custo」、データ抽出を担う「BuleLake Exto」、社内基準となるレポートを全社共有する「BuleLake Repo」、セルフBIツールの「BuleLake Pivo」、データ実験環境の「BuleLake Labo」、データプロフェッショナル向けの何でもできる環境「BuleLake Pro」だ。
各ツールは、スクラッチでの開発から、Amazon QuickSightやTableau、Amazon WorkSpaces、Databricksまで、利用するサービスは様々。「一見するとリッチにみえるが、ライセンス課金のツールは利用者を見定め、従量課金のツールは使い過ぎないようガバナンスを効かせることで、コストを抑えながら運用している」と丸山氏。

秘伝4:目的やレベル別に多種なツールを整備
秘伝5:4万人が同じ基準で見られるダッシュボード
これらのツールの中で、レポート展開を担う「BuleLake Repo」は、グループの4万人が“同じ目線で”データを捉えられるダッシュボードとして、Amazon QuickSightを用いて開発された。「部門や部署が増えると、独自の集計や分析も多くなり、基準を合わせて物事を進めるのが難しくなる」と丸山氏。
工夫したポイントは2つ。ひとつは、アカウント作成を自動化したこと。ANAのグループウェアが備えるIdPと、Amazon CognitoとAWS Lambdaを掛け合わせて、アカウントを自動作成する仕組みを構築して、運用負荷を軽減した。
もうひとつは、Amazon QuickSightをそのまま利用しなかったこと。データ活用のハードルをできる限り下げられるよう、QuickSightは埋め込まれているが、誰でも気軽にデータ分析ができるよう、社内向けのサービスとして整備している。
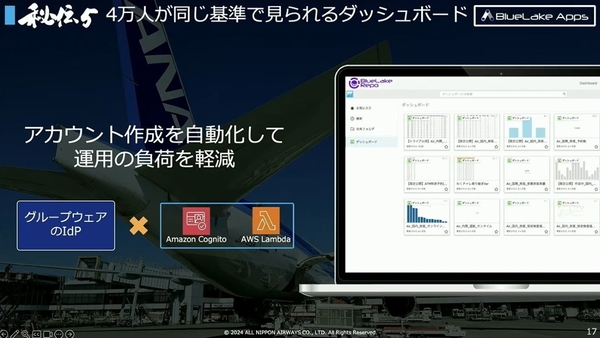
秘伝5:4万人が同じ基準で見られるダッシュボード
秘伝6:抽出ツールは必要(現時点では)
「BuleLake Exto」はデータ抽出を担うツールだ。「データ活用のツールを整理する中で、データ抽出は分析の目的にはならないため不要だと言われたが、実際はそう簡単ではない」と丸山氏。社内のデータ活用の状況から、データ抽出をなくすのはまだ早いと判断。しかし、意外にもデータ抽出に特化したサービスは市場で見当たらなかった。
そこで、AWSのサービスを駆使して、ドラッグアンドドロップで利用できるSQLツールをスクラッチで開発。まだリリース間もないため機能は単純なものだが、今後、GUIで作成したSQLをレシピとして保存できる機能や、社員同士でレシピを共有できる機能などを追加していく予定だ。
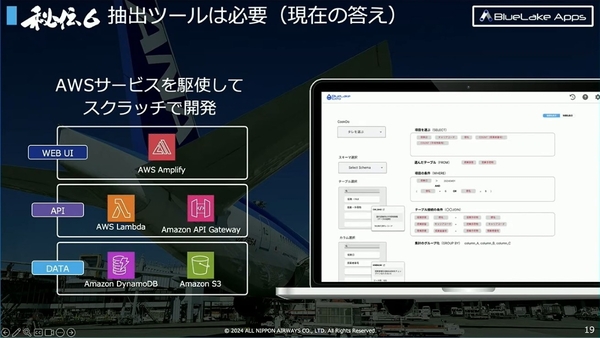
秘伝6:抽出ツールは必要
秘伝7:ユーザーフレンドリーな“ナレッジの宝庫”
続いては、基盤であるBlueLakeとツールであるBlueLake Appsの橋渡しをする“データカタログ”についてだ。とにかくデータやUIがわかりやすく、データに関する質問やナレッジが共有できること、そして、コストパフォーマンスの高さが求められた。
高機能なデータプロフェッショナル向けのデータカタログはあったものの、利用目的が合わず、データカタログもAWSのサービスで内製することに。
ANAのデータカタログ「Moana」は、無駄な情報は省き、わかりやすいUIとなるよう設計された。カタログ機能に加えて、社内用語をまとめたDictionary機能や、社員同士がつながるSNS機能も搭載。今ではデータの民主化を促進する上で欠かせないツールに成長しているという。
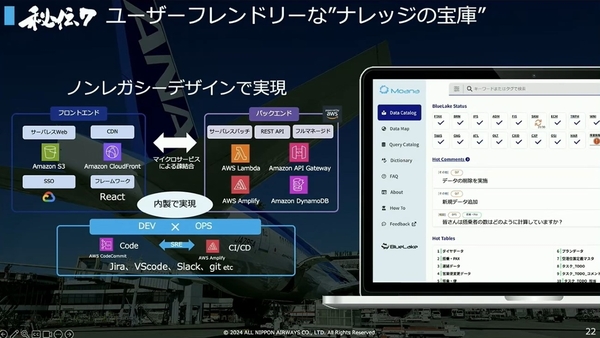
秘伝7:ユーザーフレンドリーな“ナレッジの宝庫”
秘伝8:AWSは自社の世界観を表現できる
仕組みの最後の秘訣は、AWSのブランディングのしやすさだ。「データの民主化の推進は、マーケティング活動そのもの。常に『BlueLake Apps』の名でコミュニケーションするため、元の製品名で呼ぶ人はいない」と語る。企業が世界観を表現する上で、AWSのカスタマイズ性の高さが有効であったという。

秘伝8:AWSは自社の世界観を表現できる









