Λειτουργικά μοτίβα δικτύων ονομάζονται οι στατιστικά υπερ-αντιπροσωπευμένοι υπο-γράφοι που απαντώνται σε δίκτυα του πραγματικού κόσμου (εν αντιθέσει με δίκτυα που έχουν προκύψει από κάποιο μοντέλο τυχαιοποιημένου δικτύου).
ΗΒιολογίατων ζωντανών οργανισμών περιλαμβάνει πολλά περίπλοκα δίκτυα ανεξάρτητων γεγονότων και αλληλεπιδράσεων μεταξύ των βιομορίων. Παραδείγματα τέτοιων δικτύων που περιλαμβάνουν δίκτυα που σχετίζονται μετημεταγραφή, ή την ρύθμιση των γονιδίων, δίκτυα που αφορούν τηναλληλεπίδραση πρωτεΐνης-πρωτεΐνης (PPI), μεταβολικά μονοπάτια και άλλα, έδειξαν πως τα δίκτυα από διάφορους τομείς, βιολογικούς ή μη, περιλαμβάνουν αρκετά μικρά τοπολογικά πρότυπα τα οποία είναι τόσο συχνά, που είναι απίθανο να εμφανίζονται τυχαία, αλλά σχετίζονται με κάποια λειτουργική και καίρια σημασία. Διαφορετικά δίκτυα τείνουν να έχουν διαφορετικά σύνολα τέτοιων συχνά εμφανιζόμενων δομών. Αυτές οι δομές αναφέρονται ως «μοτίβα δικτύων» και είναι γνωστές ως το απλό δομικό στοιχείο ενός σύνθετου δικτύου. Η ανακάλυψη αυτή προκάλεσε ένα πλήθος ερευνητικών προσπαθειών την προηγούμενη δεκαετία καιο συγκεκριμένος τομέας έχει ακόμα πολλές προοπτικές νέων ανακαλύψεων ακόμα και σήμερα.[1]Ταμοτίβα δικτύων έχουν επίσης μελετηθεί καισε άλλους τομείς, όπως των ηλεκτρονικών κυκλωμάτων, της διανομής ενέργειας, της οικολογίας (food web), του Διαδικτύου, των μέσων κοινωνικής δικτύωσης και φυσικά των μοριακών δομών.
Μία πιθανή επιβεβαίωση γιατην σημαντικότητα των μοτίβων αποτελεί η συντήρησή τους. Κατά την εξέλιξη, η συντήρηση είναι άρρηκτα συνδεδεμένη μετην σημαντικότητα. Συγκεκριμένα, σταβιολογικά δίκτυαη συντήρηση των πρωτεϊνών σε ένα μοτίβο μπορεί να είναι ενδεικτική της βιολογικής σημαντικότητας αυτού του μοτίβου. Εάν υπάρχει εξελικτική πίεση στονα διατηρηθούν συγκεκριμένα μοτίβα, θα αναμενόταν τα στοιχεία πουτα απαρτίζουν να είναι εξελικτικά συντηρημένα καινα έχουν αναγνωρίσιμα ορθολογικά στοιχεία καισε άλλους οργανισμούς.[2]
Η ιδέα παρουσιάστηκε πρώτη φορά το 2002 από τον Uri Alon καιτην ομάδα του, όταν τα μοτίβα δικτύων βρέθηκαν στα δίκτυα γονιδιακής ρύθμισης (μεταγραφή) του βακτηρίου E.coliκαι έπειτα σε μεγαλύτερα δίκτυα φυσικών δικτύων.[3] Από τότε, ένας σημαντικός αριθμός μελετών διεξάγεται πάνω σε αυτό το αντικείμενο. Κάποιες από τις μελέτες εστιάστηκαν σε βιολογικά δίκτυα, ενώ άλλες στην υπολογιστική θεωρία των μοτίβων των δικτύων. Οι βιολογικές μελέτες προσπαθούν να ερμηνεύσουν τα μοτίβα που ανιχνεύονται στα βιολογικά δίκτυα. Ένα διακριτό σύνολο μοτίβων δικτύων αναγνωρίστηκε σε διάφορους τύπους βιολογικών δικτύων, όπως τανευρωνικά δίκτυακαιτα δίκτυα που αφορούν αλληλεπιδράσεις πρωτεϊνών.[4]Η έρευνα εστιάστηκε στη βελτίωση των ήδη υπαρχόντων εργαλείων ανίχνευσης μοτίβων προκειμένου να βοηθήσει στις βιολογικές έρευνες καινα επιτρέψει την ανάλυση μεγαλύτερων δικτύων.
Κάθε δίκτυο αποτελείται από κόμβους, που αντιπροσωπεύουν τα γονίδια και κατευθυνόμενες ακμές, που απεικονίζουν τον έλεγχο ενός γονιδίου από έναν παράγοντα μεταγραφής που κωδικοποιείται από κάποιο άλλο γονίδιο. Μετον τρόπο αυτό δημιουργούνται μοτίβα γονιδίων που ρυθμίζουν αναμεταξύ τους τα επίπεδα μεταγραφής τους.[5] Αναλύοντας τέτοια μεταγραφικά δίκτυα παρατηρείται εμφάνιση των ίδιων μοτίβων πολλές φορές καισε ποικίλους οργανισμούς, από τα βακτήρια έως καιτον άνθρωπο. Τα μοτίβα των δικτύων εντοπίστηκαν αρχικά στο βακτήριο E.coli καθώς καιστο ζυμομύκητα S.cerevisiae, λόγω της πληθώρας των δεδομένων που έχουν συγκεντρωθεί.[6]Οι λειτουργίες που σχετίζονται μεταπιο κοινά μοτίβα δικτύων έχουν ερευνηθεί και αποδειχθεί με αρκετές ερευνητικές μελέτες τόσο σε θεωρητικό όσο και πειραματικό επίπεδο και παρακάτω παρουσιάζονται ορισμένα από ταπιο κοινά μοτίβα μαζί μετη λειτουργία τους.
Η αρνητική αυτορρύθμιση (NAR) συμβαίνει όταν ένας παράγοντας μεταγραφής καταστέλλει την μεταγραφή του ίδιου τουτου γονιδίου. Το μοτίβο αυτό εμφανίζεται στους μισούς περίπου καταστολείς της E.coliκαισε πολλούς ευκαρυωτικούς καταστολείς. Έχει δειχθεί ότι εμφανίζει δύο ειδών σημαντικές λειτουργίες: 1) επιταχύνει το χρόνο απόκρισης των κυκλωμάτων των γονιδίων και 2) μειώνει τη μεταβλητότητα από κύτταρο σε κύτταρο σε πρωτεϊνικό επίπεδο.[7]
Η θετική αυτορρύθμιση (PAR) συμβαίνει όταν ένας παράγοντας μεταγραφής ενισχύει τα επίπεδα της δικής του παραγωγής. Το μοτίβο αυτό λειτουργεί αντίθετα συγκριτικά μετο μοτίβο NAR, καθώς επιβραδύνει το χρόνο απόκρισης των κυκλωμάτων των γονιδίων και συνήθως ενισχύει τη μεταβλητότητα από κύτταρο σε κύτταρο σε επίπεδο πρωτεϊνών.[7]
Το μοτίβο FFL αποτελείται από 3 γονίδια: τον ρυθμιστή Χ, ο οποίος ρυθμίζει τοΨ, και ένα γονίδιο Ζπου ρυθμίζεται από το γονίδιο Ψ. Το μοτίβο αυτό εμφανίζεται σε εκατοντάδες συστήματα γονιδίων στηνE.coliκαιστη ζύμη καθώς καισε άλλους οργανισμούς. Κάθε μία από τις τρεις ρυθμιστικές αντιδράσεις μπορεί να είναι είτε ενεργοποίηση είτε καταστολή καιγιατο λόγο αυτό υπάρχουν 8 πιθανοί τύποι FFL, που χωρίζονται σε συνδεδεμένους καιμη-συνδεδεμένους. Δύο από τους 8 πιθανούς τύπους απαντώνται συχνότερα στα μεταγραφικά δίκτυα, οC1-FFLκαιοI1-FFL.[7]
Το μοτίβο SIM χαρακτηρίζεται από ένα ρυθμιστή Χο οποίος ρυθμίζει μία ομάδα γονιδίων-στόχων ενώ ταυτόχρονα ρυθμίζει καιτον εαυτό του. Σε ιδανικές περιπτώσεις δεν υπάρχει άλλος ρυθμιστής γιατη ρύθμιση των γονιδίων-στόχων. Κύρια λειτουργία του μοτίβου αυτού είναι η συντονισμένη έκφραση μιας ομάδας γονιδίων με κοινή λειτουργία.[7]
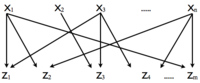
Το μοτίβο DOR χαρακτηρίζεται από ένα πλήθος ρυθμιστών που ελέγχουν συνδυαστικά ένα πλήθος γονιδίων εξόδου, δηλαδή πολλαπλές είσοδοι μεταφράζονται σε πολλαπλές εξόδους. Γιατην πλήρη κατανόηση του μοτίβου απαιτούνται τόσο τα βέλη που συνδέουν την είσοδο μετην έξοδο όσο καιοι ακριβείς λειτουργίες εισόδου. Στο δίκτυο της E.coli απαντώνται αρκετά μοτίβα DOR που περιλαμβάνουν εκατοντάδες γονίδια εξόδου, καθένα από τα οποία είναι υπεύθυνο γιαμια πληθώρα βιολογικών λειτουργιών. Αντίστοιχα μοτίβα απαντώνται καιστο δίκτυο της ζύμης.[7]
Τα βιολογικά καιτα μηχανικά δίκτυα έχει αποδειχθεί πως παρουσιάζουν μοτίβα, δηλαδή μία μικρή ομάδα χαρακτηριστικών προτύπων, που συναντώνται πολύ συχνά. Τα μοτίβα αυτά διαδραματίζουν σημαντικό ρόλο σταΠολύπλοκα Βιολογικά Δίκτυα. Έχουν προταθεί ποικίλες λύσεις γιατο καίριο πρόβλημα της ανίχνευσης μοτίβων.[8] Έτσι, υπάρχουν πολλοί διαφορετικοί αλγόριθμοι γιατην ανίχνευση μοτίβων, οι οποίοι παρουσιάζονται συνοπτικά παρακάτω.
Ο αλγόριθμος "mfinder" αποτελεί το πρώτο εργαλείο γιατην εξόρυξη μοτίβων και εφαρμόζει δύο ειδών αλγορίθμους: την πλήρη απαρίθμηση καιτη μέθοδο δειγματοληψίας.[9]
Ο αλγόριθμος "Mavisto" καλείται ανιχνευτής ευέλικτων σχημάτων και χρησιμοποιείται γιατην εξαγωγή συχνά χρησιμοποιούμενων υπο-γράφων ενός δικτύου εισόδου καιτην εισαγωγή τους στο σύστημα που καλείται Mavisto.[10]
Ο συγκεκριμένος αλγόριθμος "FANMOD" παρέχει σημαντικές βελτιώσεις σε σχέση μετον mfinder και χρησιμοποιείται τόσο για κατευθυνόμενα όσο καιγιαμη-κατευθυνόμενα δίκτυα.[11]
Ο αλγόριθμος "NeMoFinder" χρησιμοποιείται γιατην εύρεση μοτίβων μεγέθους έως 12, για δίκτυα που αφορούν μόνο PPI, τα οποία παρουσιάζονται ως μη-κατευθυνόμενοι γράφοι. Δεν μπορεί να χρησιμοποιηθεί γιατην εύρεση μοτίβων σε κατευθυνόμενα δίκτυα.[12]
Οαλγόριθμος Grochow-Kelis επινοήθηκε από τους Grochow και Kellis το 2007 και αποτελεί το πρώτο παράδειγμα μοτιβο-κεντρικού αλγορίθμου. Ο Grochow χρησιμοποίησε ρήξη της συμμετρίας με χαρτογράφηση προκειμένου να μετρήσει την συχνότητα του υπογράφου. Χρησιμοποιεί τα πακέτα ‘geng’ and ‘directg’ από τον McKay γιανα παράγει όλους τους μη ισομετρικούς υπογράφους μεγέθους κ. Στη συνέχεια, ελέγχει αν κάποιος από αυτούς είναι μοτίβο.[13]
Το 2008 οι Alon et al. παρουσίασαν μία προσέγγιση προκειμένου να βρίσκονται μη επαγόμενοι υπογράφοι. Αυτή η τεχνική (Color-Coding Approach) δουλεύει σεμη κατευθυνόμενα δίκτυα, όπως το PPI. Εφαρμόζεται για υπογράφους μεγέθους μέχρι και 10.[14]
Αναπτύχθηκε από τον Omidi et al. το 2009. Αυτός ο μοτιβο-κεντρικός αλγόριθμος MODA χρησιμοποιεί το μοτίβο ανάπτυξης δένδρου, το οποίο αποκαλείται δένδρο επέκτασης (expansion tree) καιτο οποίο χρησιμοποιεί ρήξη της συμμετρίας γιανα παράγει μοναδικές επεκτάσεις. Στη συνέχεια, χρησιμοποιεί χαρτογράφηση του πρώτου επιπέδου αυτού του δένδρου. Οι πληροφορίες που πήρε από το προηγούμενο επίπεδο χρησιμοποιούνται για κάθε επόμενο επίπεδο. Αξίζει να σημειωθεί πως αυτός ο αλγόριθμος υλοποιεί μία εξελιγμένη στρατηγική σε κάθε επίπεδο, αντιθέτως μετον αλγόριθμο Grochow.[15]
Αποτελεί έναν αλγόριθμο (Αλγόριθμος Kavosh) ο οποίος είναι δικτυο-κεντρικός. Χρησιμοποιεί το μοτίβο ανάπτυξης δένδρου γιανα απαριθμήσει όλα τα μεγέθη υπό-γράφων του δικτύου. Ο συγκεκριμένος αλγόριθμος διατρέχει όλο το δένδρο γιανα εξασφαλίσει ότι κάθε υποψήφιο μοτίβο συναντάται μόνο μία φορά.[16]
Το 2010 οι Pedro Ribeiro και Fernando Silva πρότειναν μία νέα δομή δεδομένων (Δομή δεδομένων G-Tries) γιατην αποθήκευση μίας ομάδας υπογράφων, η οποία ονομάστηκε g-trie. Αυτή η δομή δεδομένων αποθηκεύει τους υπογράφους ανάλογα με τις δομές τους και βρίσκει αν καθένας από αυτούς εμφανίζεται σε ένα μεγαλύτερο γράφο. Μία από τις πλέον αξιοσημείωτες πτυχές αυτής της δομής δεδομένων είναι η ανακάλυψη των μοτίβων των δικτύων. Έτσι, δεν υπάρχει ανάγκη να βρεθούν κάποιοι τυχαία πουδεν ανήκουν στο βασικό δίκτυο.[17]
↑Shen-Orr SS, Milo R, Mangan S, Alon U (2002). «Network motifs in the transcriptional regulation network of Escherichia coli». Nature Genetics31 (1): 64-68. doi:10.1038/ng881.
↑Milo R, Itzkovitz S, Kashtan N, Levitt R, Shen-Orr S, Ayzenshtat I, Sheffer M, Alon U (2004). «Superfamilies of designed and evolved networks». Science303 (5663): 1538-1542. doi:10.1126/science.1089167.
↑Babu MM, Luscombe NM, Aravind L, Gerstein M, Teichmann SA (2004). «Structure and evolution of transcriptional regulatory networks». Current Opinion in Structural Biology14 (3): 283-291. doi:10.1016/j.sbi.2004.05.004.
↑Conant GC, Wagner A (2003). «Convergent evolution of gene circuits». Nature Genetics34 (3): 264-266. doi:10.1038/ng1181.
↑N. Kashtan, S. Itzkovitz, R. Milo and U. Alon (2004). «Efficient sampling algorithm for estimating subgraph concentrations and detecting network motifs». Bioinformatics20 (11): 1746-1758. doi:10.1093/bioinformatics/bth163.
↑Milo R, Shen-Orr SS, Itzkovitz S, Kashtan N, Chklovskii D, Alon U (2002). «Network motifs:simple building blocks of complex networks». Science298 (5594): 824-827. doi:10.1126/science.298.5594.824.
↑Schreiber F, Schwobbermeyer Η (2005). «MAVisto: a tool for the exploration of network motifs». Bioinformatics21 (17): 3572-3574. doi:10.1093/bioinformatics/bti556.
↑Kashtan N, Itzkovitz S, Milo R, Alon U (2004). «Efficient sampling algorithm for estimating sub-graph concentrations and detecting network motifs». Bioinformatics20 (11): 1746-1758. doi:10.1093/bioinformatics/bth163.
↑Chen J, Hsu W, Li Lee M (2006). «NeMoFinder: dissecting genome-wide protein-protein interactions with meso-scale network motifs». the 12th ACM SIGKDD international conference on Knowledge discovery and data mining: 106-115. doi:10.1093/bioinformatics/bth163.
↑Grochow JA, Kellis M (2007). Network Motif Discovery Using Sub-graph Enumeration and Symmetry-Breaking, σελ. 92-106. doi:10.1007/978-3-540-71681-5_7.
↑Alon N, Dao P, Hajirasouliha I, Hormozdiari F, Sahinalp S.C (2008). «Biomolecular network motif counting and discovery by color coding». Bioinformatics24: 241-249.
↑Omidi S, Schreiber F, Masoudi-Nejad A (2009). «MODA: an efficient algorithm for network motif discovery in biological networks». Genes Genet Syst84 (5): 385-395. doi:10.1266/ggs.84.385.
↑Kashani ZR, Ahrabian H, Elahi E, Nowzari-Dalini A, Ansari ES, Asadi S, Mohammadi S, Schreiber F, Masoudi-Nejad A (2009). «Kavosh: a new algorithm for finding network motifs». Bioinformatics10 (318). doi:10.1186/1471-2105-10-318.
↑Ribeiro P, Silva F. «G-Tries: an efficient data structure for discovering network motifs"». ACM 25th Symposium On Applied Computing - Bioinformatics Track: 1559-1566.