| この 記事は 英語版の対応するページを翻訳することにより充実させることができます。(2023年3月)翻訳前に重要な指示を読むには右にある[表示]をクリックしてください。
- 英語版記事を日本語へ機械翻訳したバージョン(Google翻訳)。
- 万が一翻訳の手がかりとして機械翻訳を用いた場合、翻訳者は必ず翻訳元原文を参照して機械翻訳の誤りを訂正し、正確な翻訳にしなければなりません。これが成されていない場合、記事は削除の方針G-3に基づき、削除される可能性があります。
- 信頼性が低いまたは低品質な文章を翻訳しないでください。もし可能ならば、文章を他言語版記事に示された文献で正しいかどうかを確認してください。
- 履歴継承を行うため、要約欄に翻訳元となった記事のページ名・版について記述する必要があります。記述方法については、Wikipedia:翻訳のガイドライン#要約欄への記入を参照ください。
- 翻訳後、
{{翻訳告知|en|Autoencoder|…}}をノートに追加することもできます。
- Wikipedia:翻訳のガイドラインに、より詳細な翻訳の手順・指針についての説明があります。
|
オートエンコーダ(自己符号化器、英: autoencoder)とは、機械学習において、ニューラルネットワークを使用した次元圧縮のためのアルゴリズム。2006年にジェフリー・ヒントンらが提案した[1]。
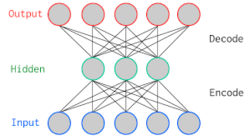
オートエンコーダは3層ニューラルネットにおいて、入力層と出力層に同じデータを用いて教師なし学習させたものである。教師データが実数値で値域がない場合、出力層の活性化関数は恒等写像、(すなわち出力層は線形変換になる)が選ばれることが多い。中間層の活性化関数も恒等写像を選ぶと結果は主成分分析とほぼ一致する。実用上では、入力と出力の差分をとることで、異常検知に利用されている。
特性と限界[編集]
オートエンコーダは次元圧縮に必要な特性を有するように設計されている。
オートエンコーダは中間層の次元数  が入出力層の次元数
が入出力層の次元数  より小さいように制約されている。なぜなら
より小さいように制約されている。なぜなら  の場合、オートエンコーダは恒等変換のみで再構成誤差ゼロを達成できてしまう[2]。
の場合、オートエンコーダは恒等変換のみで再構成誤差ゼロを達成できてしまう[2]。
オートエンコーダは次元圧縮を実現するが、これは良い表現学習を必ずしも意味しない[3]。 を小さくすることで入力中の情報量が多い(より少量で画像を再構成できる)特徴のみが保存されると期待されるが(c.f. 非可逆圧縮)、これが特徴量として優れているとは一概に言えない。
AEが再構成および次元圧縮を学習できる理由が理論的に解析されている。
オートエンコーダネットワーク  はエンコーダネットワーク
はエンコーダネットワーク  とデコーダネットワーク
とデコーダネットワーク  からなる。決定論的な解釈においてAEは「再構成された入力」を直接出力する。すなわち
からなる。決定論的な解釈においてAEは「再構成された入力」を直接出力する。すなわち  である。
である。
確率論的解釈[編集]
AEは確率モデルの観点から深層潜在変数モデルの一種とみなせ、次のように定式化できる:

すなわち  は分布パラメータ
は分布パラメータ  を出力し分布を介して
を出力し分布を介して  が得られると解釈できる[4][5]。AEではエンコーダが決定論的に振舞うため、写像の条件付き確率分布(デルタ関数
が得られると解釈できる[4][5]。AEではエンコーダが決定論的に振舞うため、写像の条件付き確率分布(デルタ関数  )で表現される。 の決定論的性質より を集約して表現するとAEは次の確率論的表現で表される:
)で表現される。 の決定論的性質より を集約して表現するとAEは次の確率論的表現で表される:

AEの学習には平均二乗誤差(MSE, L2)をはじめ様々な損失関数が(決定論的な視点から)経験的に使われている。これは経験的なものであって学習収束保証があるとは限らない。理論的な研究により、いくつかの損失関数では  に特定の分布を設定したinfomax学習として定式化できることがわかっている。
に特定の分布を設定したinfomax学習として定式化できることがわかっている。
固定分散正規分布モデル[編集]
「分散が固定された正規分布  」を考えると負の対数尤度
」を考えると負の対数尤度  は以下になる:
は以下になる:

これは  と
と  の二乗誤差と解釈できる。すなわち、
の二乗誤差と解釈できる。すなわち、  のNLL最小化と
のNLL最小化と  の二乗誤差最小化は同等とみなせる[6]。換言すれば、二乗誤差で学習されたオートエンコーダモデルは「最尤推定された固定分散正規分布 からの最頻値サンプリングモデル」であるとみなせる。
の二乗誤差最小化は同等とみなせる[6]。換言すれば、二乗誤差で学習されたオートエンコーダモデルは「最尤推定された固定分散正規分布 からの最頻値サンプリングモデル」であるとみなせる。
オートエンコーダには様々な変種・派生モデルが存在する。以下はその一例である:
- 変分オートエンコーダー(VAE)
- Contractive AutoEncoder
- Saturating AutoEncoder
- Nonparametrically Guided AutoEncoder
- Unfolding Recursive AutoEncoder
スパース・オートエンコーダ[編集]
スパース・オートエンコーダ(英: sparse autoencoder)とは、フィードフォワードニューラルネットワークの学習において汎化能力を高めるため、正則化項を追加したオートエンコーダのこと。ただし、ネットワークの重みではなく、中間層の値自体を0に近づける。
Stacked autoencoder[編集]

バックプロパゲーションでは通常、中間層が2層以上ある場合、極小解に収束してしまう。そこで、中間層1層だけでオートエンコーダを作って学習させる。次に、中間層を入力層と見なしてもう1層積み上げる。これを繰り返して多層化したオートエンコーダをつくる方法をstacked autoencoderと言う。
Denoising AutoEncoder[編集]
入力層のデータにノイズを加えて学習させたもの。制約付きボルツマンマシンと結果がほぼ一致する。ノイズは確率分布が既知であればそれに従ったほうが良いが、未知である場合は一様分布で良い。
- ^ Geoffrey E. Hinton; R. R. Salakhutdinov (2006-07-28). “Reducing the Dimensionality of Data with Neural Networks”. Science 313 (5786): 504-507. https://www.cs.toronto.edu/~hinton/absps/science.pdf.
- ^ "autoencoder where Y is of the same dimensionality as X (or larger) can achieve perfect reconstruction simply by learning an identity mapping." Vincent. (2010). Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion.
- ^ "The criterion that representation Y should retain information about input X is not by itself sufficient to yield a useful representation." Vincent. (2010). Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion.
- ^ "a deterministic mapping from X to Y, that is, ... equivalently
 ... The deterministic mapping
... The deterministic mapping  that transforms an input vector
that transforms an input vector  into hidden representation
into hidden representation  is called the encoder." Vincent. (2010). Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion.
is called the encoder." Vincent. (2010). Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion.
- ^ "
 . This mapping
. This mapping  is called the decoder. ... In general
is called the decoder. ... In general  is not to be interpreted as an exact reconstruction of , but rather in probabilistic terms as the parameters (typically the mean) of a distribution
is not to be interpreted as an exact reconstruction of , but rather in probabilistic terms as the parameters (typically the mean) of a distribution  " Vincent. (2010). Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion.
" Vincent. (2010). Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion.
- ^ " is called the decoder ...
 ... associated loss function
... associated loss function  ...
...  ... This yields
... This yields  ... This is the squared error objective found in most traditional autoencoders." Vincent. (2010). Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion.
... This is the squared error objective found in most traditional autoencoders." Vincent. (2010). Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion.



